Pourquoi vos projets d’IA échouent : la crise silencieuse de la qualité des données
“Pourquoi mon projet IA ne fonctionne pas ?”
C’est une question que se posent aujourd’hui de nombreux CDO, CIO et Data Quality Managers, après des mois d’investissement, de tests et d’entraînements modèles… pour des résultats décevants.
Et dans plus de 70 % des cas, ce n’est pas l’algorithme qui est en cause.
👉 Ce sont les données.
Selon plusieurs études, 70 à 80 % des projets IA échouent, soit deux fois plus que les projets IT traditionnels. Et ce taux continue d’augmenter à mesure que l’IA se déploie dans de nouveaux cas d’usage métiers.
En IA, une vérité persiste : garbage in, garbage out.
📌 Avant d’investir davantage dans vos modèles, encore faut-il savoir si vos données sont réellement prêtes pour l’IA. C’est précisément ce que permet d’évaluer le free trial de Tale of Data, sur vos propres jeux de données.
La qualité des données : le fondement invisible (et souvent négligé) de l’IA
Les modèles d’intelligence artificielle ne font que refléter les données qu’on leur fournit. Si ces données sont floues, incomplètes ou biaisées, même le modèle le plus avancé produira des résultats erronés, inutilisables ou dangereux.
Voici les principales failles rencontrées dans les projets IA liés à la donnée :
- Données inexactes ou incomplètes → apprentissage inefficace
- Jeux de données biaisés → reproduction ou amplification des discriminations
- Pénurie ou excès de données → sous-apprentissage ou surajustement
- Données mal labellisées ou cloisonnées → incapacité à détecter les bons patterns
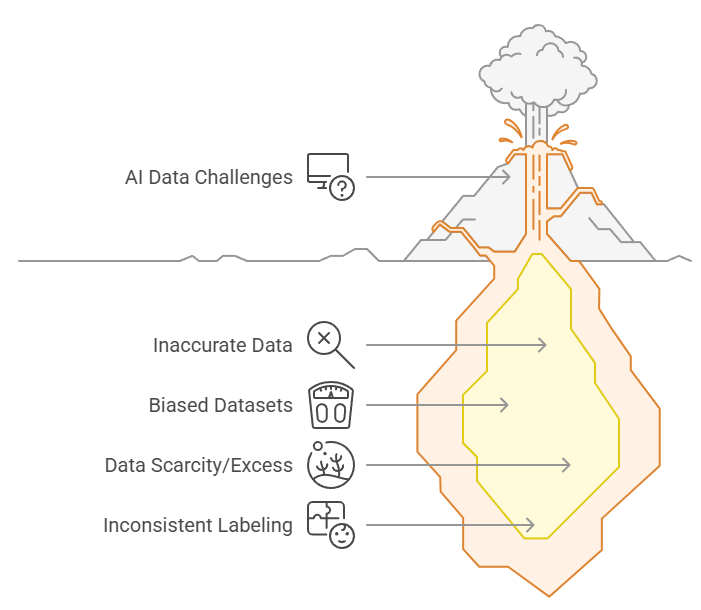
📌 Ces problèmes ne sont pas théoriques. Ils peuvent être mesurés, objectivés et priorisés avant même de lancer ou relancer un projet IA.
Le free trial de Tale of Data permet justement d’identifier ces failles en quelques minutes, sans code, directement sur vos données existantes.
👉Évaluer la qualité de vos données en free trial
Etudes de cas : quand la mauvaise qualité des données fait échouer l’IA
🧪 IBM Watson for Oncology
Malgré un investissement de 62 millions de dollars de la part du MD Anderson Cancer Center, le projet a échoué à fournir des recommandations utiles en oncologie.
La cause : le modèle avait été entraîné sur des données hypothétiques, plutôt que sur des dossiers patients réels.
De plus, la nature opaque des décisions du système — une “boîte noire” — a fortement diminué la confiance des médecins, conduisant à l’abandon du projet.
🧑💼 Amazon – Outil de recrutement IA
L’outil de recrutement développé par Amazon a été entraîné sur des données historiques d’embauche fortement biaisées en faveur des hommes.
Résultat : l’algorithme a systématiquement déclassé les CV mentionnant des activités ou groupes féminins, et valorisé des formulations associées au langage masculin.
Après plusieurs tentatives pour corriger le biais, le projet a finalement été abandonné.
✈️ Air Canada – Chatbot IA
Un client a reçu une information incorrecte sur la politique de remboursement via le chatbot IA d’Air Canada.
Un tribunal a jugé la compagnie juridiquement responsable des informations fournies par le bot, et l’a contrainte à honorer le remboursement.
Ce cas souligne les risques légaux concrets liés à l’IA déployée sur des données erronées.
📰 Apple Intelligence – Résumé d’actualités (2025)
En 2025, Apple a déployé un système d’IA générative chargé de résumer des articles de presse.
Le problème : l’outil a inventé des informations et les a attribuées à tort à des sources crédibles comme la BBC.
Face à la polémique, Apple a été contraint de suspendre la fonctionnalité, et de réévaluer la manière dont elle étiquette les contenus générés par l’IA.
Les conséquences d’une mauvaise qualité des données
- Des millions d’euros perdus en développement, en formation, en infrastructure
- Des mois ou années gaspillés dans la mauvaise direction
- Une perte de confiance, tant en interne qu’auprès des utilisateurs finaux
- Des risques de non-conformité : RGPD, CSRD, e-invoicing, Bâle III, etc.
Comment garantir le succès de vos projets IA : un socle de qualité des données solide
Les organisations doivent traiter la donnée comme un actif stratégique, et mettre en place un cadre robuste de Data Quality avant même de construire des solutions IA.
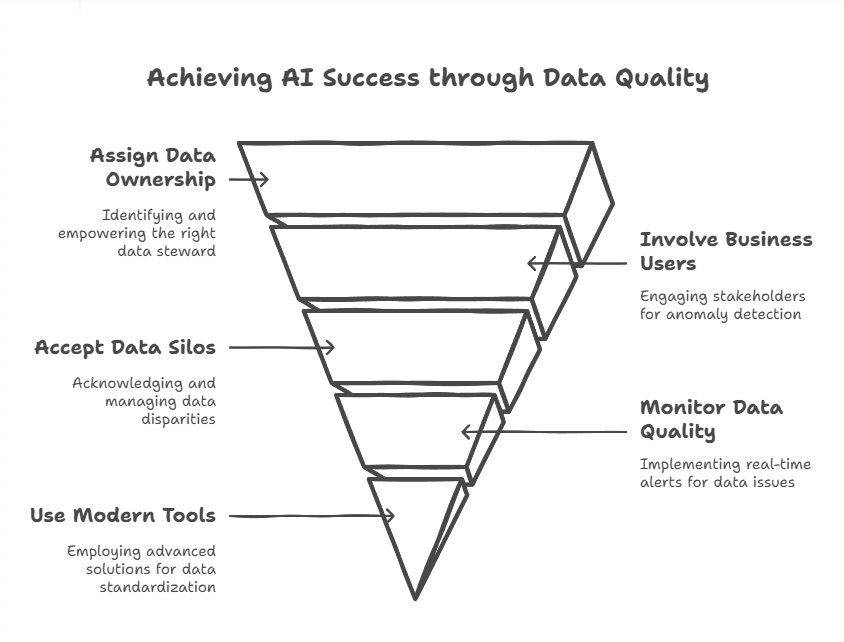
Cela implique :
- Attribuer la responsabilité de la qualité des données à la bonne personne : cette personne est souvent déjà dans l’organisation. Elle doit avoir une connaissance métier et data approfondie. Ces deux piliers ne peuvent pas être externalisés.
- Impliquer les utilisateurs métiers dans les processus de qualité des données : ce sont eux qui comprennent le mieux les anomalies ayant un impact concret sur le fonctionnement de l’entreprise.
- Accepter que les silos de données sont inévitables : ils reflètent la diversité des usages et structures des départements. Plutôt que de chercher à les supprimer, il faut utiliser des outils capables de réconcilier les données issues de sources hétérogènes en temps réel, en amont des algorithmes IA.
- Surveiller la qualité des données en continu (Data Content Observability) : il faut une capacité de monitoring automatique qui envoie des alertes pertinentes et contextualisées aux bonnes personnes dès qu’un risque réel apparaît.
- Utiliser des outils modernes pour les opérations de standardisation et de remédiation : abandonner les scripts Python accumulés, souvent opaques et peu maintenables. La priorité est à la lisibilité, à la transparence et à la collaboration entre les métiers et les équipes data.
📌 Ces principes ne doivent pas rester théoriques. Ils peuvent être appliqués rapidement, sans refonte du SI, pour valider leur impact réel.
Le free trial de Tale of Data permet de mettre en œuvre ces pratiques sur un périmètre maîtrisé, avant toute généralisation.
👉 Mettre ces principes en pratique en free trial
Vous lancez un projet IA ? Commencez par la qualité de vos données.
Chez Tale of Data, nous aidons les entreprises à sécuriser leurs projets IA en bâtissant un socle robuste de qualité des données.
Notre plateforme accessible en no-code, permet :
- d’industrialiser la remédiation des données,
- de surveiller en continu leur qualité (observabilité de contenu),
- de documenter chaque transformation,
- et de rendre les métiers autonomes, sans dépendance technique.
Avec Tale of Data, vos projets IA reposent enfin sur des bases fiables, traçables et conformes.
👉 Tester la qualité de vos données en free trial (30 jours)
Sur vos propres données. Sans code. Sans engagement.
📅 Vous êtes CDO, CIO ou porteur d’un projet IA stratégique ?
Ne laissez pas vos données compromettre vos résultats.

Témoignage client TotalEnergies

Qualité des données : pourquoi les projets bloquent côté IT
