Intégration des données cliniques : comment construire des pipelines fiables pour les Life Sciences
L’intégration des données cliniques ne consiste plus seulement à connecter des systèmes.
Dans les Life Sciences, elle consiste à construire des pipelines de données fiables, capables de préserver la qualité, le sens et la traçabilité des données lorsqu’elles circulent entre EDC, LIMS, CTMS, ePRO, extraits EHR, fournisseurs d’imagerie, plateformes de wearables, fichiers CRO et environnements analytiques.
Les essais cliniques ne souffrent pas d’un manque de systèmes. La plupart des sponsors, CRO, biotechs et medtechs s’appuient déjà sur des plateformes spécialisées. La zone fragile se situe entre ces systèmes : exports, scripts, fichiers Excel, tables de staging, fichiers partenaires, réconciliations manuelles et transformations non documentées.
C’est souvent là que l’intégration des données cliniques se fragilise.
Un pipeline peut déplacer les données correctement d’un point de vue technique. Mais s’il transfère aussi des valeurs manquantes, des identifiants sujets incohérents, des formats invalides, des mappings peu clairs ou des transformations mal documentées, le dataset aval ne peut pas être considéré comme réellement fiable.
Pour les équipes cliniques, data et IT, l’objectif n’est donc plus seulement d’extraire, transformer et charger des données. L’objectif est de connecter, valider, réconcilier, documenter et monitorer les données cliniques avant leur utilisation en aval.
Cet article explique ce que signifie l’intégration des données cliniques, pourquoi elle devient critique dans les Life Sciences, où les problèmes apparaissent, et comment les équipes peuvent construire des pipelines de données cliniques plus fiables.
Hub intégration des données cliniques
Utilisez cet article comme point d’entrée central pour notre série de contenus sur l’intégration des données cliniques. Commencez par le guide pratique Approfondir les sujets associés Évaluez vos propres données |
Qu'est-ce que l'intégration des données cliniques ?
L’intégration des données cliniques désigne le processus qui consiste à connecter, harmoniser et préparer des données cliniques issues de plusieurs sources afin d’obtenir un dataset fiable, exploitable et traçable.
Dans un contexte data général, l’intégration signifie souvent déplacer des données d’un système source vers un système cible. Dans la recherche clinique, cette définition est trop limitée.
La donnée ne doit pas seulement arriver. Elle doit arriver avec les bons identifiants, les bons formats, les bonnes unités, la bonne terminologie, le bon statut de validation et un historique clair des traitements appliqués.
Un résultat de laboratoire exporté depuis un LIMS n’est pas réellement intégré si l’unité est manquante ou si l’identifiant sujet ne se réconcilie pas avec l’export EDC. Un dataset issu de wearables n’est pas prêt pour l’analyse si les timestamps, valeurs manquantes ou identifiants participants sont traités dans des scripts non documentés. Un fichier partenaire peut sembler complet tout en créant des problèmes si sa structure change sans alerte.
L’intégration des données cliniques couvre tout le cycle de vie de l’essai :
- au démarrage, les équipes alignent les données de screening, d’éligibilité, de sites ou de fournisseurs ;
- pendant la conduite de l’étude, elles réconcilient les données EDC, LIMS, ePRO, imagerie, wearables et partenaires ;
- avant la revue ou l’analyse, elles préparent des datasets cohérents et traçables pour les usages aval.
L’objectif n’est pas simplement de centraliser les données cliniques. Il est de les rendre exploitables, explicables et fiables.
Pourquoi l’intégration des données cliniques devient plus complexe
Les essais cliniques génèrent davantage de données, issues de plus de sources, avec plus de dépendances entre systèmes.
Les données EDC ne sont plus le seul socle opérationnel. Les sponsors et CRO travaillent de plus en plus avec des outils ePRO, des composantes d’essais décentralisés, des fournisseurs d’imagerie, des laboratoires centraux et locaux, des extraits EHR, des objets connectés et des sources de données en vie réelle.
Chaque source apporte de la valeur. Mais chaque source ajoute aussi de nouveaux formats, identifiants, calendriers de transfert et risques qualité.
Les amendements au protocole ajoutent une autre difficulté. Lorsque le protocole évolue, la structure des données peut évoluer avec lui : nouveaux champs, fenêtres de visite, endpoints, fichiers fournisseurs ou règles de validation. Un pipeline construit autour de scripts statiques peut fonctionner pour la première version d’une étude et devenir fragile après deux ou trois changements.
L’IA renforce également les attentes.
Les équipes cliniques veulent utiliser les données pour le risk-based monitoring, l’analyse de cohortes, la prévision opérationnelle, la stratification des patients ou la génération de preuves futures. Mais des données cliniques prêtes pour l’IA nécessitent plus que du volume. Elles exigent des entrées fiables, des définitions cohérentes, des transformations documentées et un lineage de la source jusqu’aux usages aval.
C’est pourquoi l’intégration des données d’essais cliniques n’est plus seulement un sujet IT. Elle devient une couche critique pour la qualité des données, la traçabilité et la confiance sur tout le cycle de vie de l’essai.
Où l'intégration des données cliniques échoue
L’intégration des données cliniques se fragilise généralement au moment des passages entre systèmes.
Les systèmes sources peuvent être corrects lorsqu’ils sont pris isolément. Le problème apparaît lorsque les données doivent être combinées, transformées, réconciliées ou réutilisées.
Un identifiant sujet peut ne pas correspondre entre un export EDC et un fichier laboratoire. Une date de visite peut tomber en dehors de la fenêtre attendue. Une valeur de laboratoire peut utiliser une unité différente selon le site ou le fournisseur. Un fichier partenaire peut arriver avec une structure modifiée. Un dataset issu de wearables peut produire des données haute fréquence qui ne s’alignent pas naturellement avec les visites prévues au protocole.
Ces problèmes peuvent sembler techniques au départ. En réalité, ce sont des problèmes de qualité des données cliniques.
Lorsque les données intégrées ne peuvent pas être réconciliées ou expliquées, les équipes perdent du temps à investiguer les écarts, ouvrir des queries, corriger les mappings et reconstruire la confiance dans le dataset final.
Les points de rupture les plus fréquents sont :
- identifiants sujets, sites ou visites incohérents ;
- champs obligatoires manquants ou incomplets ;
- incohérences d’unités, formats ou terminologies ;
- règles de mapping et de transformation non documentées ;
- scripts fragiles maintenus par un nombre réduit de spécialistes ;
- détection tardive des problèmes qualité ;
- lineage limité entre les données sources et les datasets aval.
C’est pourquoi les outils d’intégration des données cliniques doivent aller au-delà de la connectivité. Ils doivent aider les équipes à comprendre ce qui se passe dans le pipeline.
Pourquoi l’ETL traditionnel ne suffit pas pour l’intégration des données cliniques
Les outils ETL traditionnels ont été conçus pour déplacer et transformer les données efficacement. Cette efficacité reste importante, mais elle ne résout pas l’ensemble du problème clinique.
Un pipeline peut réussir techniquement même si des champs critiques sont manquants, si les identifiants ne se réconcilient pas ou si les formats sont incohérents. Du point de vue IT, le transfert a fonctionné. Du point de vue des données cliniques, le pipeline a créé un risque aval.
Les transformations cliniques ne sont pas neutres. Une conversion d’unité, une règle de mapping, un choix de déduplication, une variable dérivée ou un enregistrement exclu peuvent influencer l’interprétation. Si ces décisions sont cachées dans des scripts ou des feuilles de calcul, le dataset final devient plus difficile à revoir et à expliquer.
La maintenance est un autre défi. Les essais cliniques évoluent. Les amendements au protocole, changements de fournisseurs, nouvelles sources et mises à jour de structures de fichiers peuvent casser la logique d’intégration. Si chaque changement nécessite un nouveau projet de scripting, les équipes cliniques restent dépendantes d’un petit nombre de spécialistes techniques.
Pour les équipes Life Sciences, l’intégration des données cliniques doit faire plus que transporter les données. Elle doit valider, réconcilier, documenter et monitorer les données pendant leur circulation.
Comment construire un pipeline fiable d’intégration des données cliniques
Un pipeline fiable d’intégration des données cliniques commence par la visibilité.
Avant de construire ou modifier un flux, les équipes doivent comprendre d’où viennent les données, où elles vont, quels identifiants sont utilisés, quelles transformations sont appliquées et quels processus aval consomment le résultat.
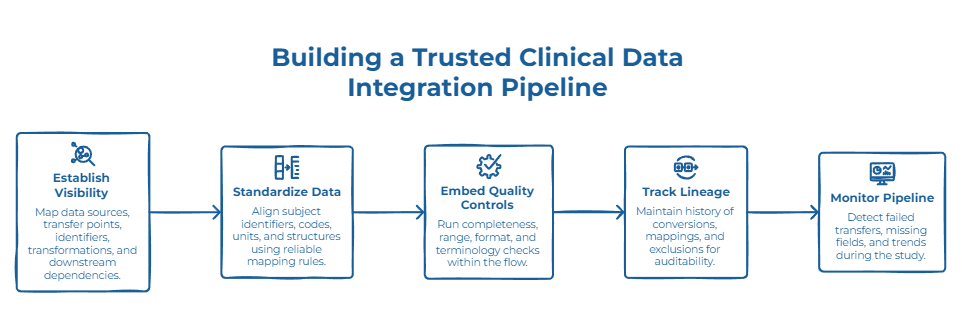
Sans vision claire des systèmes sources, points de transfert, identifiants sujets, structures de visites, terminologies contrôlées et dépendances aval, le travail d’intégration devient réactif.
Une fois les flux cartographiés, la priorité est la standardisation.
Les identifiants sujets, codes sites, fenêtres de visite, unités de laboratoire, structures de fichiers et listes de référence doivent être alignés entre les systèmes. Cela ne signifie pas forcer tous les systèmes dans un même modèle interne. Cela signifie créer des règles de mapping fiables pour que les données cliniques puissent circuler sans perdre leur sens.
Les contrôles qualité doivent ensuite être intégrés directement dans le pipeline.
Les contrôles de complétude, validations de plages, validations de formats, règles de réconciliation, contrôles terminologiques et règles métier doivent s’exécuter dans le flux de données, et non uniquement lors d’une revue tardive.
Le lineage est tout aussi important.
Les équipes cliniques, data et qualité doivent comprendre comment une valeur est passée de la source au résultat final. Si une valeur de laboratoire a été convertie, si un champ a été mappé, si un identifiant sujet a été réconcilié ou si un enregistrement a été exclu, cet historique doit pouvoir être consulté sans reconstruire manuellement le processus.
Enfin, les pipelines d’intégration doivent être monitorés dans le temps.
Les équipes ont besoin de visibilité sur les transferts échoués, champs manquants, écarts de réconciliation, tendances anormales, risques de doublons et problèmes récurrents au niveau des sources. L’objectif est de détecter les problèmes pendant que l’étude est en cours, et non uniquement au moment de préparer le dataset d’analyse.
Que rechercher dans des outils d’intégration des données cliniques ?
Les meilleurs outils d’intégration des données cliniques ne doivent pas seulement connecter des systèmes. Ils doivent aider les équipes Life Sciences à construire des pipelines gouvernés, réutilisables et observables.
Une approche solide de l’intégration des données cliniques doit permettre de :
- connecter des sources de données cliniques accessibles ;
- transformer les données sans excès de scripting ;
- appliquer des contrôles qualité directement dans le pipeline ;
- réconcilier les identifiants, visites, unités et valeurs de référence ;
- documenter la logique de transformation et le lineage ;
- monitorer la qualité des données dans le temps ;
- opérer autour des systèmes cliniques existants sans les remplacer.
Pour les grands groupes pharmaceutiques, cette approche réduit la fragmentation dans des écosystèmes cliniques complexes, notamment lorsque plusieurs fournisseurs, régions, études et environnements legacy sont impliqués.
Pour les entreprises pharma, biotech et medtech de taille intermédiaire, elle réduit la dépendance aux scripts spécifiques et donne davantage d’autonomie aux équipes cliniques sur les tâches récurrentes d’intégration et de réconciliation.
C’est dans cette direction qu’évoluent les services de gestion intégrée des données cliniques et les plateformes modernes : passer de projets d’intégration ponctuels à des pipelines gouvernés où qualité, lineage et monitoring sont intégrés au flux.
Comment Tale of Data facilite l'intégration des données cliniques
Tale of Data est une plateforme no-code de Data Integration avec la qualité des données intégrée dans chaque pipeline.
Pour les équipes clinical data, cela signifie construire des flux de préparation gouvernés dans lesquels les données peuvent être connectées, transformées, réconciliées, validées, documentées et monitorées avant leur utilisation en aval.
Tale of Data ne remplace pas les EDC, CTMS, LIMS, ePRO, EHR ou autres systèmes cliniques spécialisés. La plateforme opère autour des systèmes existants et avant les usages aval, à partir d’exports structurés, fichiers, bases de données, environnements cloud, tables de staging ou sources accessibles.
Avec Tale of Data, les équipes peuvent :
- concevoir des pipelines visuels no-code pour les flux récurrents de données cliniques ;
- lancer un Flash Audit pour identifier les trous de complétude, conflits d’identifiants, incohérences de formats, risques de doublons et problèmes d’intégration ;
- appliquer des contrôles qualité directement dans le pipeline ;
- réconcilier des datasets issus de plusieurs sources cliniques ;
- documenter les transformations, mappings, corrections et règles grâce au lineage ;
- monitorer les indicateurs qualité dans le temps avant que les problèmes n’affectent le reporting, l’analyse ou les workflows aval.
Cette approche est particulièrement utile lorsque l’intégration des données d’essais cliniques dépend d’exports récurrents issus d’EDC, LIMS, ePRO, systèmes partenaires ou plateformes data internes.
Au lieu de maintenir des scripts isolés que seuls quelques spécialistes comprennent, les équipes travaillent avec des flux visuels plus simples à revoir, adapter et partager.
Lorsqu’un amendement au protocole modifie un champ, une structure de visite ou un format de transfert, le pipeline peut être mis à jour de manière plus claire et plus contrôlée.
L’objectif est simple : connecter les données cliniques, contrôler leur qualité et garder chaque transformation importante explicable.
Télécharger le guide Qualité des données Pharma
Le guide Qualité des données Pharma est un guide pratique d’auto-évaluation pour les équipes Life Sciences qui travaillent sur des pipelines de données fiables, l’audit-readiness et des fondations data prêtes pour l’IA.

Vous y trouverez :
- une auto-évaluation en 20 questions pour mesurer votre maturité en qualité des données ;
- un cadre pour construire des flux de préparation de données gouvernés ;
- des exemples pratiques autour des données cliniques, produits et fournisseurs ;
- un glossaire des notions essentielles de qualité et d’intégrité des données.
Télécharger le guide Qualité des données Pharma
Conclusion : passer de systèmes connectés à des pipelines cliniques fiables
L’intégration des données cliniques ne consiste plus seulement à connecter des systèmes.
Dans les Life Sciences, elle consiste à construire des pipelines fiables qui préservent le sens, la qualité et la traçabilité des données lorsqu’elles circulent dans l’écosystème clinique.
Les systèmes existent déjà. Les données existent déjà. La zone fragile est souvent celle qui les relie : exports, scripts, réconciliations manuelles, transformations non documentées et contrôles qualité tardifs.
Les organisations qui améliorent cette couche cessent de traiter l’intégration, la qualité et le lineage comme des chantiers séparés. Elles construisent des pipelines qui valident les données pendant qu’ils les connectent, documentent les transformations lorsqu’elles se produisent et monitorent la qualité pendant que les données circulent.
Pour les équipes cliniques, cela permet d’obtenir des données plus fiables pour le monitoring, l’analyse, le reporting et les futures initiatives IA. Pour les équipes data et IT, cela réduit la dépendance aux scripts fragiles et aux projets d’intégration ponctuels. Pour les équipes qualité, cela rend la préparation des données plus facile à revoir et à expliquer.
La prochaine étape est simple : commencer par comprendre l’état réel de vos données cliniques.
Lancez un Flash Audit pour identifier les problèmes d’intégration, de qualité et de traçabilité, ou téléchargez le guide Qualité des données Pharma pour structurer votre évaluation plus globale de la qualité des données.

Qualité des données d’essais cliniques : guide

Gestion des données pharmaceutiques : guide
