Fiabilisation des données : définition, méthode et bonnes pratiques
La fiabilisation des données ne consiste pas seulement à corriger des erreurs. Elle consiste surtout à éviter que les mêmes anomalies réapparaissent à chaque import, chaque reporting ou chaque changement de système.
La plupart des organisations ne manquent pas de corrections de données. Elles accumulent plutôt des corrections qui ne tiennent pas dans le temps. Un fournisseur dupliqué est fusionné dans un système, puis réapparaît au prochain import. La correction a bien eu lieu, mais elle n’a jamais été reliée à une règle métier, un workflow ou un système de référence.
Ce guide explique ce que recouvre la fiabilisation des données, comment elle se distingue des termes voisins, les problèmes les plus courants qu’elle traite, la raison structurelle pour laquelle les corrections ne durent pas, à quoi ressemble une méthode complète, et ce qu’il faut rechercher dans un logiciel de fiabilisation — avec l’exemple d’un déploiement réel ayant fait passer une tâche récurrente d’une semaine à deux heures.
Qu’est-ce que la fiabilisation des données ?
La fiabilisation des données consiste à corriger, contrôler et réintégrer les données issues d’un audit qualité, afin de garantir leur exactitude et leur cohérence avant leur utilisation en aval. C’est l’équivalent français de ce que les équipes anglophones appellent data remediation.
Elle suit généralement quatre étapes opérationnelles :
- Détecter — identifier les anomalies, doublons, valeurs manquantes ou données sensibles via un scan automatisé.
- Corriger — dédupliquer, normaliser les formats, compléter les champs manquants ou réconcilier les données avec une source de référence.
- Contrôler — valider la correction au regard des règles métier avant qu’elle ne soit appliquée.
- Réintégrer — repousser la donnée corrigée dans les systèmes qui en dépendent, de façon contrôlée et traçable.
Ce qui distingue une vraie fiabilisation d’un nettoyage ponctuel, c’est la seconde moitié de cette séquence : le contrôle et la réintégration. N’importe qui peut corriger un tableur une fois. Fiabiliser une donnée, c’est s’assurer que cette correction est reproductible et reliée à la source — pour que la même erreur ne réapparaisse pas le trimestre suivant.
Pourquoi la fiabilisation compte pour le reporting, les opérations et l’IA
Avant la méthode, l’enjeu. La fiabilisation empêche les erreurs de se propager dans les reportings, les opérations et les décisions automatisées.
Elle réduit le temps passé à corriger les mêmes champs à chaque cycle, au lieu d’analyser les résultats. Elle renforce la capacité d’audit, puisque chaque correction laisse une trace documentée. Et à mesure que les organisations alimentent leurs systèmes d’automatisation et d’IA, la fiabilisation devient un prérequis plutôt qu’une réflexion après coup : un modèle ou un agent ne vaut que ce que valent les données sur lesquelles il s’appuie.
Sans cette couche, chaque processus en aval hérite du même risque non résolu.
Fiabilisation vs nettoyage de données vs correction ponctuelle
Ces trois notions sont souvent confondues, mais elles désignent des périmètres différents.
- La correction ponctuelle est la plus étroite : régler une erreur précise sur un enregistrement précis, sans implication de processus ni de récurrence.
- Le nettoyage de données, ou data cleansing, est plus large : un passage sur un jeu de données pour corriger plusieurs problèmes à la fois — doublons, formats, valeurs manquantes — généralement dans le cadre d’un projet ponctuel ou périodique.
- La fiabilisation des données est la plus complète : elle inclut la correction et le nettoyage, mais ajoute la couche de contrôle et de réintégration qui rend la correction traçable, auditable et reliée à une règle empêchant la récurrence.
En pratique, le nettoyage répond à la question : « Ce jeu de données est-il propre aujourd’hui ? »
La fiabilisation répond à une question plus durable : « La même anomalie sera-t-elle encore détectée le mois prochain, et puis-je prouver comment elle a été corrigée ? »
Les problèmes de données les plus courants à fiabiliser
Une poignée de problèmes récurrents concentre l’essentiel du travail de fiabilisation en pratique :
- Fiches fournisseurs ou clients dupliquées — la même entité enregistrée plusieurs fois sous des noms, adresses ou identifiants fiscaux légèrement différents.
- Identifiants fiscaux invalides ou manquants — numéros de TVA, codes SIRET ou identifiants d’entreprise incorrects qui bloquent les contrôles de conformité.
- Attributs produit ou centres de coûts incohérents — unités mal renseignées, dimensions manquantes ou codes de classification obsolètes.
- Données sensibles mal classifiées — champs personnels ou confidentiels non signalés ou non protégés selon la politique en vigueur.
- Référentiels obsolètes — catalogues produits ou bases fournisseurs qui ne reflètent plus la réalité actuelle.
- Data lineage cassé ou non documenté — champs transformés tant de fois que personne ne peut expliquer l’origine de la valeur actuelle.
Aucun de ces problèmes n’est exotique. Ce sont les conséquences ordinaires d’une croissance rapide, de fusions de systèmes ou d’une dépendance trop longue à des processus manuels.
Exemples de fiabilisation par fonction métier
La même logique s’applique différemment selon l’endroit où vit la donnée :
- Finance — fournisseurs dupliqués, numéros de TVA ou SIRET manquants, paiements porteurs de risque de fraude.
- Données produit — dimensions incohérentes, unités mal renseignées, références catalogue obsolètes.
- CRM et données clients — contacts dupliqués, adresses invalides, champs obligatoires incomplets.
- Conformité — données sensibles non classifiées ou non protégées selon la politique en vigueur.
- BI et reporting — indicateurs qui divergent entre équipes à cause de mappings ou de référentiels différents.
Ces exemples montrent que la fiabilisation n’est pas seulement un sujet technique. Elle touche directement la précision financière, l’efficacité opérationnelle, la conformité, la confiance dans le reporting et la préparation des données pour l’IA.
Pourquoi ces démarches échouent silencieusement
La plupart des projets échouent non pas à la détection. Les outils de profilage font émerger les doublons et formats incohérents de façon fiable. Ce qui échoue, c’est ce qui se passe après.
Un incident survenu chez Equifax en 2022 illustre le coût d’une défaillance plus en amont. Une erreur de code sur un serveur historique a généré des scores de crédit inexacts pour plus de 300 000 consommateurs entre mars et avril de cette année-là. Dans au moins un cas documenté, une erreur de 130 points a directement conduit au refus d’un crédit auto. De grands prêteurs, dont JPMorgan Chase et Wells Fargo, ont été affectés par une donnée qu’ils n’avaient aucune raison de remettre en question — et l’incident a déclenché un examen réglementaire approfondi, un recours collectif et une migration coûteuse de l’infrastructure.
La leçon est claire : une erreur non détectée dans un système, sans workflow de fiabilisation pour la surveiller, peut prendre une ampleur considérable avant que quiconque ne s’en aperçoive.
Le rôle des règles métier implicites
Voici l’endroit où la plupart de ces démarches se trompent, et cela n’a presque rien à voir avec la technologie.
Les règles métier existent presque toujours déjà — dans la tête des collaborateurs, des formules de tableur ou des scripts historiques. Le problème n’est pas qu’elles soient absentes. Le problème, c’est qu’elles sont invisibles.
Une règle comme « les commandes de moins de 50 € sont des retours non facturables » fonctionne bien tant qu’une seule personne l’applique de façon cohérente. Au moment où elle doit déclencher une correction automatisée ou un rapport réglementaire, elle doit devenir explicite, possédée et défendable.
C’est là que les équipes IT se retrouvent prises en étau : formaliser une règle de leur propre initiative leur fait porter un risque métier qu’elles n’étaient pas censées assumer ; refuser d’agir sans validation métier leur vaut d’être accusées de bloquer l’avancement. Gartner identifie l’absence de règles métier formalisées et clairement possédées comme une cause majeure d’échec de la gouvernance des données — non pas parce que les règles manquent, mais parce que leur responsabilité n’a jamais été répartie.
C’est pour cette raison qu’une fiabilisation entièrement dépendante de scripts IT a tendance à s’enliser : personne ne possède la règle, donc personne ne maintient la correction une fois le système modifié.
Méthode : détection, correction, contrôle, réintégration
-
Une méthode qui tient à l’échelle suit la même boucle, quelle que soit la plateforme :
- Scanner et détecter. Se connecter aux systèmes source et faire émerger automatiquement les anomalies, doublons, champs manquants et données sensibles.
- Suggérer et appliquer les corrections. Recommander une correction fondée sur des règles métier définies et des référentiels de référence.
- Contrôler avant diffusion. Valider les corrections au regard des mêmes règles métier avant qu’elles ne se propagent en aval.
- Réintégrer avec traçabilité. Repousser la donnée corrigée dans les systèmes cibles avec un historique clair de ce qui a changé, quand et selon quelle règle.
Cette boucle distingue une vraie fiabilisation d’un simple nettoyage. Un nettoyage s’arrête quand le rapport a l’air correct. Une fiabilisation durable s’arrête quand la même erreur dispose d’une règle permanente qui l’intercepte automatiquement la prochaine fois — avec une trace claire de sa résolution.
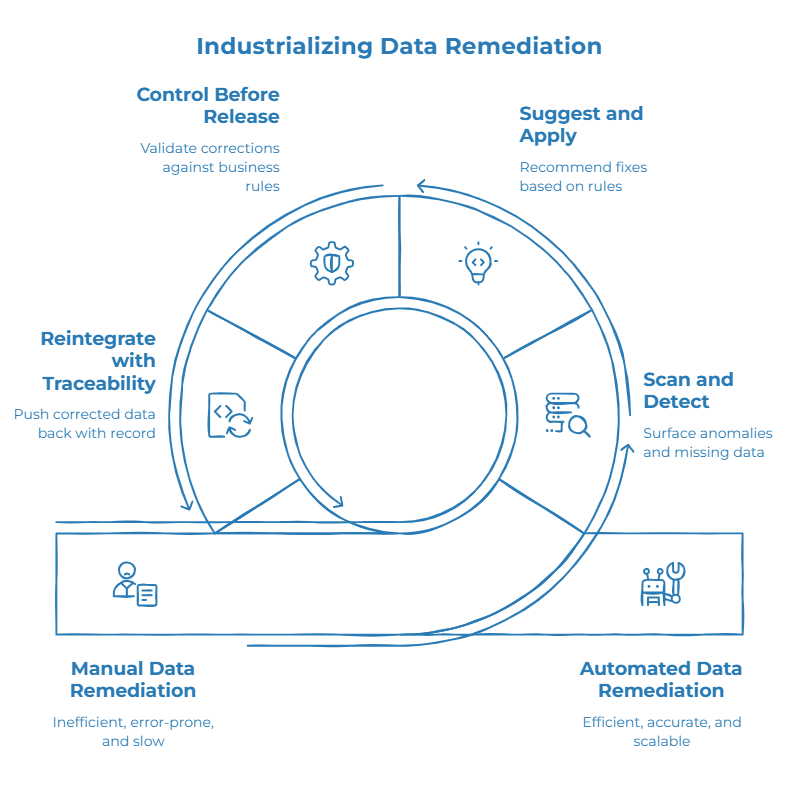
En pratique, Manutan, le plus grand fournisseur européen B2B de fournitures de bureau et équipements IT, avait besoin d’industrialiser sa fiabilisation sur un catalogue de 700 000 références dans 17 pays — un travail qui reposait auparavant sur des scripts Python manuels. Selon Mbery Ngom, Data Quality Analyst chez Manutan, un cas d’usage qui prenait une semaine avec des scripts Python a été traité en deux heures une fois reconstruit comme un workflow réutilisable et possédé par le métier — combinant deux sources de données, détectant les doublons produits et vérifiant la complétude sur des champs comme les dimensions produit, sans réécrire de code la fois suivante.
Fiabilisation manuelle vs automatisée
La fiabilisation manuelle — tableurs, scripts ponctuels, corrections au cas par cas — peut nettoyer un jeu de données une fois. Elle tient rarement à l’échelle, parce que chaque correction vit dans un fichier, possédée par une seule personne, sans lien vers une règle.
La fiabilisation automatisée transforme cette même correction en workflow permanent : la règle est définie une fois, appliquée de façon cohérente et réappliquée automatiquement chaque fois que la même anomalie réapparaît — sans que personne n’ait à se souvenir qu’elle existait.
C’est toute la différence entre corriger une erreur visible et construire un processus qui empêche cette erreur de revenir silencieusement.
Logiciels de fiabilisation des données : ce qu’il faut rechercher
Un bon logiciel de fiabilisation ne doit pas seulement détecter les erreurs. Il doit aider les équipes à transformer leurs corrections en workflows réutilisables et gouvernés.
Les capacités qui comptent le plus sont :
- Scan automatisé à travers les systèmes connectés, pas seulement des fichiers importés.
- Détection d’anomalies et de doublons, incluant le fuzzy matching pour les enregistrements quasi identiques.
- Gestion des règles métier lisible et modifiable par les équipes métier, pas seulement par l’IT.
- Workflow complet qui enchaîne détection, correction, contrôle et réintégration.
- Data lineage pour retracer tout chiffre jusqu’à sa source et ses transformations.
- Historique d’audit documentant chaque correction, par qui et pourquoi.
- Réintégration contrôlée dans les systèmes cibles — pas un export manuel que personne ne suit.
- Interfaces No-Code pour que les équipes métier possèdent les règles sans dépendre d’un backlog de développement.
Sans réintégration, sans lineage et sans appropriation métier des règles, un logiciel de fiabilisation risque de rester un simple outil de nettoyage plutôt que de devenir une véritable couche de contrôle durable.
Checklist de fiabilisation des données
Un moyen rapide d’évaluer où vous en êtes :
- Les doublons sont-ils détectés avant d’atteindre le reporting ?
- Les règles métier sont-elles documentées et clairement possédées ?
- Les corrections sont-elles validées avant réintégration ?
- Chaque correction est-elle traçable jusqu’à une source et une règle ?
- Les données corrigées peuvent-elles être réintégrées automatiquement dans les systèmes source ?
- Les anomalies récurrentes sont-elles surveillées dans le temps, pas seulement corrigées une fois ?
- Les équipes métier peuvent-elles comprendre et ajuster les règles elles-mêmes ?
- Existe-t-il un historique d’audit clair pour chaque modification ?
Si la réponse à plusieurs de ces questions n’est pas claire, le problème ne se limite pas à la qualité des données. C’est le signe que votre démarche de fiabilisation repose encore trop fortement sur des corrections manuelles.
Où se positionne Tale of Data
Tale of Data réunit détection, correction, contrôle et réintégration dans un seul workflow No-Code, conçu pour que les équipes métier et data possèdent les règles sans dépendre de l’IT à chaque changement.
Concrètement, cela signifie scanner les ERP, bases de données, fichiers et systèmes historiques à la recherche d’anomalies et de doublons, avec fuzzy matching sur les enregistrements quasi identiques ; suggérer des corrections fondées sur des règles métier et des référentiels ; valider les corrections via un workflow contrôlé avant qu’elles ne se propagent ; puis réintégrer les données corrigées avec un record lineage complet — pour que tout chiffre puisse être expliqué plus tard.
Le monitoring s’exécute en continu, et non comme un passage ponctuel.
La plateforme ne remplace pas les systèmes existants. Elle se positionne en amont, comme la couche qui rend les corrections durables plutôt que ponctuelles.
|
Une fiabilisation des données n’est pas réussie quand un jeu de données paraît propre une fois. Elle est réussie quand la même erreur est détectée plus tôt, corrigée plus vite, documentée clairement et empêchée de revenir silencieusement. Pour les organisations qui préparent leurs données pour le reporting, les opérations, l’analytique ou l’IA, la fiabilisation n’est pas une tâche secondaire. C’est la couche de contrôle qui transforme la qualité des données en processus métier reproductible. |
Vous voulez voir comment cela fonctionne sur vos propres données ?
Le moyen le plus rapide d’identifier la valeur d’une démarche de fiabilisation est de l’appliquer à un jeu de données réel. Démarrez un essai gratuit et lancez un workflow de fiabilisation sur vos propres données.
Si vous préférez d’abord comprendre où se concentrent vos problèmes de données, demandez un Flash Audit gratuit.