Product - Tale of Data
Data Quality designed to automate & scale your Data Governance
Enhance your data governance with automated quality management, ensuring accuracy, consistency, and trust at every stage. Streamline processes and effortlessly unlock your data's full potential.
Your Complete Data Quality Companion
At the heart of your data governance strategy, Tale of Data ensures your data is reliable, actionable, and fully under control.
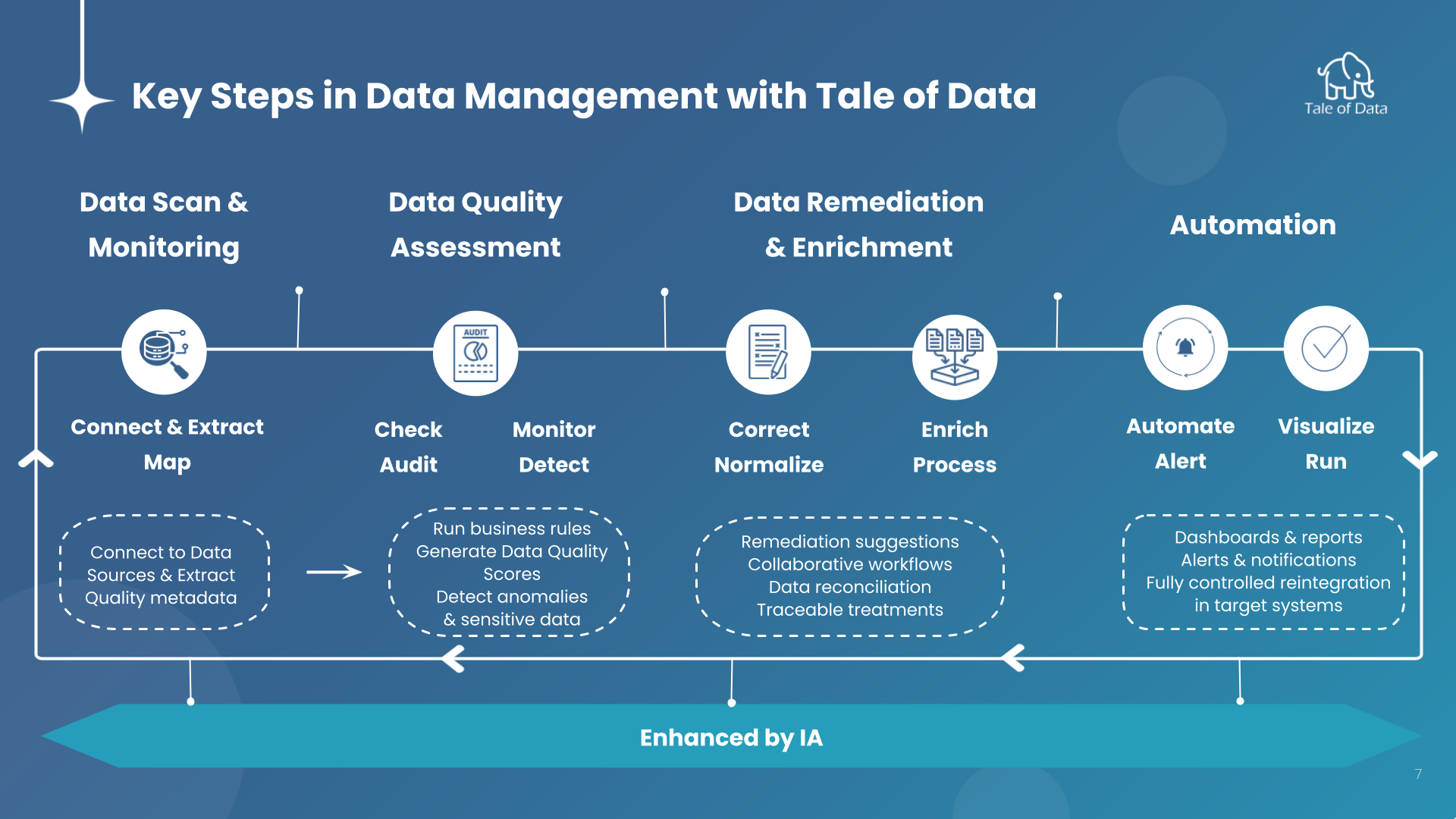
Generative AI
Read more
Generative AI
- Natural Language Prompts
- Ultra-low Token Consumption
- Context-aware Quality Reports
- Secure & Trusted AI Integration
- Data Transformation
- Transparent & Auditable AI Processing
Data Scanning
Read more
Data Scanning
- Mass Data Discovery
- Automatic Data Categorisation
- Custom Data Categorisation
- Automated scan scheduling
- Metadata sharing & standardization
- Advanced scan stats
- Real-time anomaly alerts
- Compliance Enforcement
- Sensitive and GDPR-specific monitoring
- Automatic Report Generation
Data Quality Monitoring
Read more
Data Quality Monitoring
- Mass Data Discovery
- Custom Monitoring & Alerts
- Semantic mapping
- Anomaly & Nature History
- Sensitive and GDPR-specific monitoring
- Data Quality Metrics
- Automatic Report Generation
- Custom Analysis Workflows
Data Connectivty
Read more
Data Connectivty
- Catalog view
- Dataset-level statistics
- 8+ Supported Flat File extensions
- Connect to 15+ sources with native connectors
- Select datasets and start working
- Import your own files
Data Quality Stories
Read more
Data Quality Stories
- Data visualisation
- Dashboards
- 15+ Chart types
- Control Access
- Pivot tables
- Easy Downloads
- Historical Comparison
- Filtering
- Split charts
Data Cleansing
Read more
Data Cleansing
- Flash Quality Audit
- Automatic Data Categorisation
- Custom Data Categorisation
- Time Series
- Visual SQL-like processing nodes
- Ready-to use Data Transformation Tools
- Customisable Data Quality KPIs
- Business Rules
- Interactive Data Exploration
- Built-in Data Visualisation
- Data Deduplication
- Data Remediation
- Data Enrichment
- Advanced Enrichment
Data Flow Traceability
Read more
Data Flow Traceability
- Seamless navigation
- Table Data Lineage
- Downstream Lineage
- Upstream Lineage
Data Product Certification
Read more
Data Product Certification
- Monitor Data Quality KPIs
- Business Rules
- Data Deduplication
- Data Remediation
- Data Enrichment
- Advanced Enrichment
Customers
Don't just take our word for it
Read what our customers say about us.
"It's much simpler than an Excel file, for example. The solution enables automatic processing of rows, combining different data sources, reusing workflows, and sharing them with multiple users."

Mbery Ngom
Data Quality Analyst at Manutan

Tale of Data Release Notes
Access to our Product Release Notes
Start Your Data Quality Journey Today
Transform your organization's approach to data governance with Tale of Data's comprehensive platform. Request a demo to see how we can help you achieve trusted, high-quality data across your enterprise.