Clinical Data Integration: How to Build Trusted Pipelines for Life Sciences
Clinical data integration is no longer just about connecting systems.
In life sciences, it is about building trusted data pipelines that preserve quality, meaning and traceability as clinical data moves across EDC, LIMS, CTMS, ePRO, EHR extracts, imaging vendors, wearable data platforms, CRO files and analytical environments.
Clinical trials do not suffer from a lack of systems. Most sponsors, CROs, biotechs and medtech organizations already rely on specialized platforms. The fragile part is the layer between them: exports, scripts, spreadsheets, staging tables, partner files, manual reconciliations and undocumented transformations.
That is where clinical data integration often breaks.
A pipeline may move data correctly from a technical point of view. But if it transfers missing values, inconsistent subject identifiers, invalid formats, unclear mappings or poorly documented transformations, the downstream dataset is not truly trusted.
For clinical, data and IT teams, the goal is no longer only to extract, transform and load data. The goal is to connect, validate, reconcile, document and monitor clinical data before downstream use.
This article explains what clinical data integration means, why it has become critical in life sciences, where integration issues appear, and how teams can build more trusted clinical data pipelines.
Clinical Data Integration Hub
Use this article as the central entry point for our clinical data integration content. Start with the practical guide Explore related topics Assess your own data |
What is clinical data integration?
Clinical data integration is the process of connecting, harmonizing and preparing clinical data from multiple sources into a trusted, usable and traceable dataset.
In a general data context, integration often means moving data from a source to a target system. In clinical research, this definition is too narrow.
The data must not only arrive. It must arrive with the right identifiers, formats, units, terminology, validation status and processing history.
A lab result exported from a LIMS is not truly integrated if the unit is missing or if the subject identifier does not reconcile with the EDC export. A wearable dataset is not ready for analysis if timestamps, missing values or participant IDs are handled through undocumented scripts. A partner file may look complete but still create issues if its structure changes without warning.
Clinical data integration spans the trial lifecycle:
- during start-up, teams align screening, eligibility, site or vendor data;
- during study conduct, they reconcile EDC, LIMS, ePRO, imaging, wearable and partner data;
- before review or analysis, they prepare consistent and traceable datasets for downstream use.
The objective is not simply to centralize clinical data. It is to make it usable, explainable and trusted.
Why clinical data integration has become harder
Clinical trials generate more data, from more sources, with more dependencies between systems.
EDC data is no longer the only operational backbone. Sponsors and CROs increasingly work with ePRO tools, decentralized trial components, imaging vendors, central and local labs, EHR extracts, connected devices and real-world data sources.
Each source adds value. Each source also introduces new formats, identifiers, transfer schedules and quality risks.
Protocol amendments add another layer of difficulty. When a protocol changes, the data structure may change with it: new fields, visit windows, endpoints, vendor files or validation rules. A pipeline built around static scripts may work for the first version of a study and become fragile after two or three changes.
AI is also raising expectations.
Clinical teams want to use data for risk-based monitoring, cohort analysis, operational forecasting, patient stratification and future evidence generation. But AI-ready clinical data requires more than volume. It requires reliable inputs, consistent definitions, documented transformations and lineage from source to downstream use.
This is why clinical trial data integration is no longer only an IT topic. It is becoming a critical layer for data quality, traceability and trust across the trial lifecycle.
Where clinical data integration breaks
Clinical data integration usually breaks in the handoffs.
The source systems may be correct in isolation. The issue appears when data has to be combined, transformed, reconciled or reused.
A subject identifier may not match between an EDC export and a lab file. A visit date may fall outside the expected window. A lab value may use a different unit depending on the site or vendor. A partner file may arrive with a changed structure. A wearable dataset may produce high-frequency data that does not align cleanly with protocol visits.
These issues may look technical at first. In reality, they are clinical data quality issues.
When integrated data cannot be reconciled or explained, trial teams lose time investigating discrepancies, raising queries, correcting mappings and rebuilding confidence in the final dataset.
The most common failure points include:
- inconsistent subject, site or visit identifiers;
- missing or incomplete mandatory fields;
- unit, format or terminology mismatches;
- undocumented mapping and transformation rules;
- fragile scripts maintained by a small number of specialists;
- delayed detection of quality issues;
- limited lineage between source data and downstream datasets.
This is why clinical data integration tools need to address more than connectivity. They need to help teams understand what happens inside the pipeline.
Why traditional ETL is not enough for clinical data integration
Traditional ETL tools were designed to move and transform data efficiently. Efficiency matters, but it does not solve the full clinical problem.
A pipeline may technically succeed even if critical fields are missing, identifiers do not reconcile or formats are inconsistent. From an IT perspective, the transfer worked. From a clinical data perspective, the pipeline created downstream risk.
Clinical transformations are also not neutral. A unit conversion, mapping rule, deduplication choice, derived variable or excluded record can affect interpretation. If these decisions are hidden in scripts or spreadsheets, the final dataset becomes harder to review and explain.
Maintenance is another challenge. Clinical trials evolve. Protocol amendments, vendor changes, new data sources and updated file structures can all break integration logic. If every change requires a custom scripting project, clinical teams remain dependent on a small number of technical specialists.
For life sciences teams, clinical data integration must do more than transport data. It must validate, reconcile, document and monitor data as it moves.
How to build a trusted clinical data integration pipeline
A trusted clinical data integration pipeline starts with visibility.
Before building or modifying a flow, teams need to understand where the data comes from, where it goes, which identifiers are used, which transformations are applied and which downstream processes consume the output.
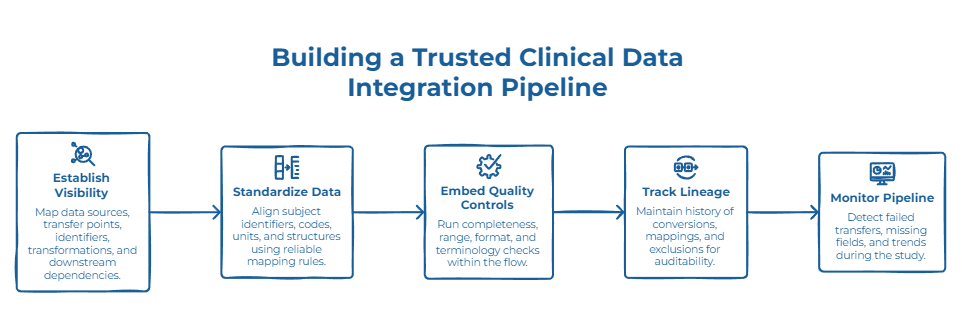
Without a clear view of source systems, transfer points, subject identifiers, visit structures, controlled terminologies and downstream dependencies, integration work becomes reactive.
Once the flows are mapped, the next priority is standardization.
Subject identifiers, site codes, visit windows, lab units, file structures and reference lists need to be aligned across systems. This does not mean forcing every system into the same internal model. It means creating reliable mapping rules so clinical data can move without losing meaning.
Quality controls should then be embedded directly into the pipeline.
Completeness checks, range validation, format validation, reconciliation rules, terminology checks and business rules should run as part of the data flow, not only as a late-stage review.
Lineage is equally important.
Clinical teams, data teams and reviewers need to understand how a value moved from source to output. If a lab value was converted, if a field was mapped, if a subject identifier was reconciled or if a record was excluded, that history should be easier to review without reconstructing the process manually.
Finally, integration pipelines should be monitored over time.
Teams need visibility into failed transfers, missing fields, reconciliation gaps, abnormal trends, duplicate risks and recurring source-level issues. The goal is to detect problems while the study is running, not only when the analysis dataset is being prepared.
What to look for in clinical data integration tools
The best clinical data integration tools should not only connect systems. They should help life sciences teams build governed, reusable and observable data pipelines.
A strong clinical data integration approach should help teams:
- connect accessible clinical data sources;
- transform data without excessive scripting;
- apply quality controls directly inside the pipeline;
- reconcile identifiers, visits, units and reference values;
- document transformation logic and lineage;
- monitor data quality over time;
- operate around existing clinical systems without replacing them.
For global pharmaceutical organizations, this helps reduce fragmentation across complex clinical ecosystems, especially when several vendors, regions, studies and legacy environments are involved.
For mid-sized pharma, biotech and medtech organizations, it can reduce dependence on custom scripts and give clinical data teams more autonomy over recurring integration and reconciliation tasks.
This is where clinical integrated data management services and platforms are moving: away from one-off integration projects and toward governed pipelines where quality, lineage and monitoring are built into the flow.
How Tale of Data supports clinical data integration
Tale of Data is a no-code Data Integration platform with data quality built into every pipeline.
For clinical data teams, this means building governed preparation flows where data can be connected, transformed, reconciled, validated, documented and monitored before downstream use.
Tale of Data does not replace EDC, CTMS, LIMS, ePRO, EHR or other specialized clinical systems. It operates around existing systems and before downstream use, on structured exports, files, databases, cloud environments, staging tables or accessible data sources.
With Tale of Data, teams can:
- design visual no-code pipelines for recurring clinical data flows;
- run a Flash Audit to identify completeness gaps, identifier conflicts, format inconsistencies, duplicate risks and integration issues;
- apply data quality controls directly inside the pipeline;
- reconcile datasets across clinical sources;
- document transformations, mappings, corrections and rules through lineage;
- monitor quality indicators over time before issues affect reporting, analysis or downstream workflows.
This is especially useful when clinical trial data integration depends on recurring exports from EDC, LIMS, ePRO, partner systems or internal data platforms.
Instead of maintaining isolated scripts that only a few specialists understand, teams can work with visual flows that are easier to review, adapt and share.
When a protocol amendment changes a field, visit structure or transfer format, the pipeline can be updated in a clearer and more controlled way.
The goal is simple: connect clinical data, control its quality and keep every important transformation explainable.
Download the Pharma Data Quality Guide
The Pharma Data Quality Guide is a practical self-assessment guide for life sciences teams working on trusted data pipelines, audit-readiness and AI-ready data foundations.

Inside the guide, you will find:
- a 20-question self-assessment to evaluate your data quality maturity;
- a framework for building governed data preparation flows;
- practical examples across clinical, product and supplier data;
- a glossary of essential data quality and data integrity terms.
Download the Pharma Data Quality Guide
Conclusion: From connected systems to trusted clinical data pipelines
Clinical data integration is no longer just about connecting systems.
In life sciences, it is about building trusted pipelines that preserve meaning, quality and traceability as data moves across the trial ecosystem.
The systems already exist. The data already exists. The fragile part is often the layer between them: exports, scripts, manual reconciliations, undocumented transformations and delayed quality checks.
The organizations that improve this layer stop treating integration, quality and lineage as separate workstreams. They build pipelines that validate as they connect, document transformations as they happen and monitor quality as data moves.
For clinical teams, this creates more reliable data for monitoring, analysis, reporting and future AI initiatives. For data and IT teams, it reduces dependence on brittle scripts and one-off integration projects. For quality teams, it makes data preparation easier to review and explain.
The next step is simple: start by understanding the current state of your clinical data.
Run a Flash Audit to identify integration, quality and traceability issues, or download the Pharma Data Quality Guide to structure your broader data quality assessment.

Clinical Trial Data Quality Management: Challenges and Solutions

Pharmaceutical Data Integrity for AI-Ready Data
