Clinical Trial Data Quality Management: Challenges, Solutions and Best Practices
Clinical trial data quality management is no longer only a cleanup exercise before database lock.
It starts much earlier: when data sources are selected, when vendors are onboarded, when exports are defined, when reconciliation rules are created and when the first records start moving between systems.
That shift matters because clinical trial data no longer comes from one place.
It can come from EDC platforms, laboratories, ePRO or eCOA tools, imaging vendors, wearables, EHR extracts, CRO files, partner transfers and statistical environments. Each source can be useful in isolation. Quality problems usually appear when those sources must be combined, reconciled and explained together.
For large pharmaceutical organizations, the challenge is scale: multiple studies, countries, CROs, vendors, affiliates and legacy systems. For mid-sized pharma, biotech and medtech organizations, the challenge is often more operational: lean data teams, manual reconciliation work, scripts maintained by a few specialists and limited time before monitoring reviews, database lock or analysis preparation.
The question is simple: can the organization trust the clinical data it uses for review, analysis, reporting and downstream decision-making?
This article explains the main clinical trial data quality management challenges and solutions, with a focus on the data layer: integration, reconciliation, traceability, data integrity in clinical trials and quality controls before downstream use.
Clinical Trial Data Quality HubUse this article as the central entry point for our clinical trial data quality content. Start with the practical guide Explore related topics Assess your own data |
What is clinical trial data quality management?
Clinical trial data quality management covers the processes, controls and tools used to keep clinical datasets accurate, complete, consistent, traceable and usable for their intended purpose.
It includes more than the data entered into an EDC system.
Clinical trial data can include laboratory results, patient-reported outcomes, imaging measurements, wearable data, adverse events, protocol deviations, monitoring data, vendor transfers and derived datasets prepared for review, analysis or reporting.
The objective is not to make every dataset perfect. That is unrealistic.
The objective is to identify the data that matters most for participant safety, study reliability, review and analysis, then ensure that this data is checked early, reconciled properly and documented clearly.
A clinical trial data quality issue can take many forms: a missing lab unit, an inconsistent subject identifier, a delayed vendor file, a mapping rule that is not documented, a dataset transformation that only one specialist understands, or a derived value that cannot be easily explained during review.
Individually, each issue may look small. Across a study, they can create delays, increase manual rework, weaken confidence in the final dataset and slow downstream workflows.
Good clinical trial data quality management combines three things: early controls, multi-source reconciliation and traceability.
Why clinical trial data quality has become harder
Clinical trial data quality has become harder to manage because trials generate more data, from more sources, with more dependencies between teams and systems.
A traditional trial could rely mainly on site-entered EDC data, scheduled monitoring and end-of-study cleaning. Modern trials often include ePRO tools, connected devices, external labs, imaging vendors, EHR extracts, decentralized trial components, real-world data sources and partner transfers.
Each additional source increases the value of the study. It also creates more handoffs where data quality can degrade.
A lab file may use a different unit than expected. A subject identifier may not match across systems. A visit date may not align with the protocol window. A vendor may change a file structure. A CRO extract may require manual mapping before it becomes usable.
Protocol amendments add another layer of complexity. New fields, visit schedules, endpoints or vendor files can affect existing data flows. If these changes are handled through undocumented scripts or manual workarounds, errors become harder to detect and harder to explain later.
AI is also raising expectations.
Clinical teams want to use data for risk-based monitoring, patient stratification, operational forecasting, cohort analysis and future evidence generation. But AI-ready clinical data requires more than data volume. It requires reliable inputs, consistent definitions, documented transformations and lineage from source to downstream use.
This is why clinical trial data quality management is becoming a data foundation topic, not only an end-of-study cleaning topic.
Clinical trial data quality management challenges and solutions
Most clinical data quality issues appear at the point where data moves between systems.
The source data may be valid in isolation. The issue begins when datasets must be combined, transformed, reconciled or reused.
1. Multi-source fragmentation
A clinical trial can generate data from EDC, LIMS, ePRO, imaging platforms, wearables, EHR extracts, CRO files and statistical environments.
Each source has its own structure, identifiers, terminology, transfer frequency and quality rules.
When these sources are combined, discrepancies can appear: subject identifiers do not match, lab units differ, visit dates fall outside expected windows, or required fields are missing.
This is not only a technical integration issue. It is a clinical data quality issue.
The solution is to map critical flows early, define reconciliation rules and apply quality checks before the final review stage.
2. Manual reconciliation work
Manual review will always play a role in clinical trials. Data managers need to review listings, raise queries, compare exports, reconcile lab data and prepare datasets.
The problem begins when manual reconciliation becomes the main quality control mechanism.
If issues are detected late, the team has fewer options. A discrepancy found shortly before database lock or analysis preparation may require urgent rework. A recurring vendor issue identified only at the end of the study may create avoidable delays.
The solution is to move checks earlier in the process, so teams can detect missing fields, identifier conflicts, format problems and reconciliation gaps while the study is still active.
3. Transformations hidden in scripts or spreadsheets
Clinical data often passes through scripts, spreadsheets or staging tables before downstream use.
A dataset may be merged with lab results. Units may be converted. Derived fields may be created. Vendor files may be mapped into an internal structure. Inconsistent records may be corrected after review.
If these steps are not documented clearly, the final dataset may be hard to explain.
The issue is not only whether the data is correct. It is whether the organization can show how it became correct.
The solution is to document transformations, mappings, corrections and reconciliation logic through clear lineage.
4. Weak visibility before downstream use
Many teams still discover data issues too late: before database lock, before analysis, before a monitoring review or during a reconciliation exercise.
By that time, the context is harder to reconstruct. The person who created a mapping may no longer be available. The vendor file may have changed. The original decision may be buried in an email, spreadsheet or script.
The solution is to monitor clinical data quality indicators over time: completeness rates, reconciliation failures, duplicate risks, delayed files, format inconsistencies and recurring source-level issues.
ICH E6(R3), ALCOA+ and data integrity in clinical trials
Clinical trial data quality is influenced by regulatory and quality expectations, including risk-based approaches and data integrity principles.
For data teams, the practical question is not to interpret regulations. It is to make sure critical data can be trusted, reviewed and explained.
From that perspective, the expectations become very concrete:
- Do teams know which data points are critical for study quality?
- Are clinical datasets checked before late-stage review?
- Are sources reconciled through documented processes?
- Can transformations be explained?
- Is the original data still traceable?
- Can data quality issues be monitored over time?
ALCOA+ is useful as a practical lens: data should be attributable, legible, contemporaneous, original, accurate, complete, consistent, enduring and available.
In clinical data preparation, this means a mapping, correction, reconciliation or transformation should not exist only in someone’s memory or in an undocumented script.
The point is not that every clinical data team needs a new system for everything. The point is that the preparation layer around clinical systems should be easier to review, reproduce and explain.
How to build a clinical trial data quality framework
A strong clinical trial data quality framework starts before late-stage cleaning.
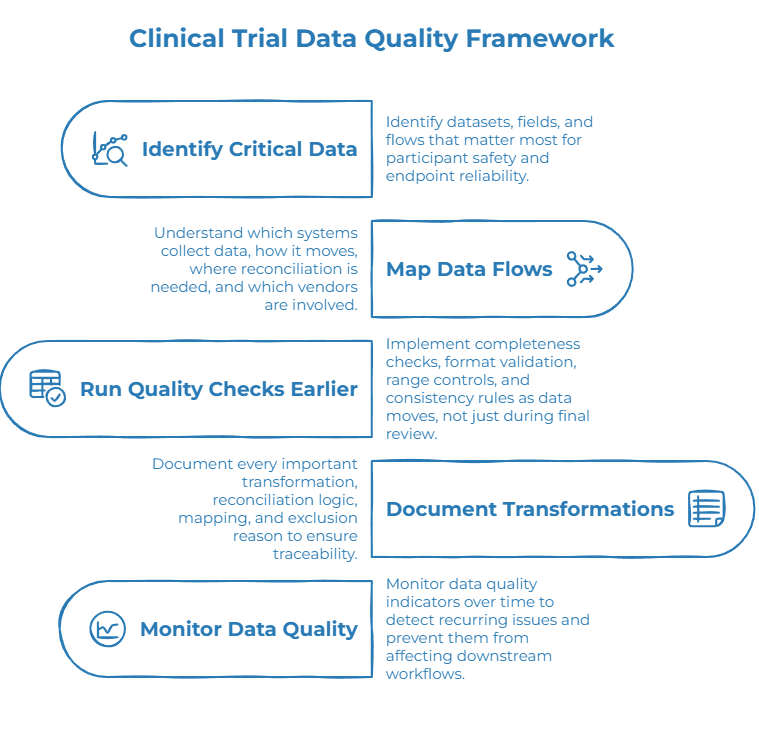
1. Identify critical data and high-risk flows
Not all data carries the same level of risk.
Teams should identify which datasets, fields and flows matter most for participant safety, endpoint reliability, review, analysis or reporting. These areas should receive stronger controls.
In practice, this may include lab values, eligibility criteria, key endpoints, adverse event-related fields, protocol deviation data, visit dates, subject identifiers or derived analysis variables.
2. Map clinical data flows
Teams need to understand which systems collect which data, how data moves between systems, where reconciliation is required and which vendors or partners are involved.
This is not only an IT exercise. It gives Clinical Data Managers, QA teams, Data Leads and Trial Managers a shared view of where quality risk can appear.
The map should include structured exports, files, databases, staging tables, scripts, vendor transfers and manual review steps.
3. Run quality checks earlier
Completeness checks, format validation, range controls, consistency rules and reconciliation alerts should run as data moves, not only during final review.
When a record fails a critical check, the issue should be visible early enough for investigation.
This reduces the burden of late-stage cleaning and helps teams address root causes instead of correcting symptoms.
4. Document transformations and reconciliation logic
Every important transformation should be easier to review and explain.
If a lab unit is converted, the rule should be documented. If subject identifiers are reconciled, the logic should be clear. If a vendor file is mapped to an internal structure, the mapping should be traceable. If records are excluded, the reason should be available.
This helps teams understand how source data became the dataset used for review, analysis or reporting.
5. Monitor data quality over time
Clinical data quality can degrade during a study.
Vendors change formats. New sources are added. Protocol amendments affect structures. Manual corrections accumulate. Scripts are updated.
Monitoring quality indicators over time helps teams detect recurring issues before they affect downstream workflows.
What to look for in clinical trial data quality management tools
Clinical trial data quality management tools should help teams control quality throughout the data lifecycle, not only inspect datasets after the fact.
A useful approach should help teams:
- profile datasets quickly;
- identify completeness gaps;
- compare data across sources;
- apply business rules;
- detect inconsistencies;
- document transformations;
- monitor quality indicators over time.
For global pharmaceutical organizations, this helps standardize practices across studies, vendors and geographies.
For mid-sized pharma, biotech and medtech organizations, it can reduce dependence on manual reconciliation and IT scripting while giving data teams more autonomy.
The goal is not to replace the EDC, LIMS, CTMS or other specialized clinical applications. The goal is to create a governed preparation and quality layer around those systems, so clinical data is checked, reconciled and documented before downstream use.
In practical terms, the right platform should support no-code or low-code workflows, embedded data quality controls, reconciliation, lineage, monitoring over time and the ability to work from structured exports, files, databases, staging tables or accessible data sources.
How Tale of Data supports clinical trial data quality management
Tale of Data is a no-code Data Integration platform with data quality built into every pipeline.
For clinical trial data teams, this means profiling, validating, reconciling, documenting and monitoring clinical data in a governed visual environment, without replacing the clinical systems already in place.
Tale of Data does not replace EDC, LIMS, CTMS, ePRO, EHR or other specialized clinical systems. It operates around existing systems and before downstream use, on structured exports, files, databases, cloud environments, staging tables or accessible data sources.
With Tale of Data, teams can:
- run a Flash Audit to identify completeness gaps, identifier conflicts, reconciliation issues, format inconsistencies, duplicate risks and potential traceability weaknesses;
- build visual no-code data workflows for recurring clinical data preparation;
- apply completeness controls, format validation, business rules, reconciliation checks, deduplication logic and consistency rules directly inside the flow;
- document transformations, mappings and reconciliation logic through lineage;
- monitor quality indicators across sources, flows or datasets over time.
For a Clinical Data Manager, QA Director, Trial Manager or CDO, this provides immediate visibility into where clinical trial data quality stands before monitoring reviews, database lock, analysis or submission preparation.
The goal is simple: detect quality issues early, explain how clinical data was prepared, and keep trusted datasets ready for downstream use.
Download the Pharma Data Quality Guide
The Pharma Data Quality Guide is a practical self-assessment guide for life sciences teams working on clinical data quality, audit-readiness and AI-ready data foundations.

Inside the guide, you will find:
- a 20-question self-assessment to evaluate your data quality maturity;
- a framework for building governed data preparation flows;
- practical examples across clinical, product and supplier data;
- a glossary of essential data quality and data integrity terms.
Download the Pharma Data Quality Guide
Conclusion: Managing clinical trial data quality before it becomes a downstream risk
Clinical trial data quality management is no longer only about cleaning data at the end of a study.
It is about improving the quality, consistency and traceability of clinical datasets from the moment data starts moving between systems.
As clinical trials become more digital and more distributed, the risk no longer sits only inside individual systems. It often appears between them: in exports, mappings, reconciliations, scripts and transformations that are difficult to review later.
The organizations that handle this well do not separate integration, quality and traceability into disconnected workstreams. They build data flows where quality checks run earlier, transformation logic is documented and teams can monitor issues before they affect timelines or downstream use.
The next step is simple: start by understanding the current state of your clinical trial data.
Run a Flash Audit to identify completeness, reconciliation, format and traceability issues, or download the Pharma Data Quality Guide to structure your broader data quality assessment.

Clinical Data Integration: Trusted Pipelines for Life Sciences

Pharmaceutical Data Management: A Life Sciences Guide
