Data Harmonization: Unifying Data Across Systems, Formats, and Business Units
Data harmonization is the process of reconciling data from different sources, formats, and systems into a consistent, comparable structure — so that the same concept means the same thing everywhere it appears.
Without it, combining data from multiple systems does not produce one trustworthy dataset. It produces several inconsistent ones stitched together, each carrying its own definitions, formats, and assumptions into a result nobody can fully trust.
This is the gap that pure data integration tools routinely miss.
Moving data from one system to another is a connectivity problem. Making that data mean the same thing once it arrives is a different problem entirely — and it is the one that actually determines whether the result is usable.
A pipeline can run flawlessly, on schedule, with zero errors logged, and still deliver a dataset where the same customer, the same product, or the same cost center is represented three different ways depending on which system it came from.
This guide covers what data harmonization involves, why integration alone is not enough to solve it, the most common scenarios where it matters, the obstacles teams typically run into, and what a complete approach looks like in practice — illustrated by a real deployment that unified product data sheets across dozens of formats into one standardized structure.
What Is Data Harmonization?
Data harmonization is the process of bringing data from different sources, formats, or systems into a consistent structure, so the same concept — a customer, a product, a cost center — is represented the same way everywhere it is used.
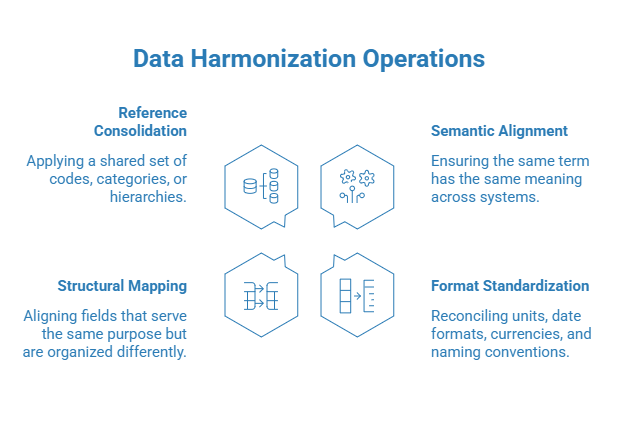
It typically involves four operations:
- Semantic alignment — making sure the same term means the same thing across systems. One system’s “active customer” should match another’s, not silently diverge.
- Format standardization — reconciling units, date formats, currencies, and naming conventions so values can actually be compared.
- Structural mapping — aligning fields that serve the same purpose but are organized differently across source systems.
- Reference consolidation — applying a shared set of codes, categories, or hierarchies instead of letting each system maintain its own.
What separates harmonization from simple data integration is the layer it operates on.
Integration moves data from point A to point B. Harmonization decides what that data actually means once it gets there — and whether two records from different systems can be safely compared, merged, or reported on together.
Data Harmonization vs. Data Integration
The two are related but answer different questions. Integration moves data. Harmonization makes it usable.
|
Data Integration |
Data Harmonization |
|
|---|---|---|
|
What it does |
Moves data between systems |
Makes data consistent across systems |
|
What it focuses on |
Connectivity |
Meaning and comparability |
|
Core question |
“Where should the data go?” |
“Does the data mean the same thing?” |
Neither replaces the other.
Integration without harmonization moves the problem instead of solving it. Harmonization without integration has nothing to act on.
The two need to work together — which is the gap most pure ETL tools leave open.
Why Data Integration Alone Isn't Enough
Most data integration tools are built to move and connect data, not to reconcile what it means.
A pipeline can extract records from five different systems, load them into a single warehouse, and still produce a dataset where “France” appears as “FR,” “France,” and “FRANCE” depending on the source — technically integrated, but practically unusable.
This is not a tooling failure. It is a scope mismatch.
ETL and integration platforms answer: “How do I move this data here?”
Harmonization answers: “Once it is here, does it actually agree with itself?”
Skipping the second question does not make it disappear. It simply moves the problem downstream, into reports that do not reconcile and dashboards nobody trusts.
Common Data Harmonization Challenges
A handful of recurring obstacles account for most of the friction in practice:
- Implicit definitions that were never written down. Each system’s notion of “active,” “valid,” or “current” often lives in someone’s head rather than in documentation, making reconciliation a discovery exercise before it becomes a technical one.
- Formats that look similar but are not. Two systems can both store dates, currencies, or addresses, while using different conventions that silently break comparisons until someone notices a report does not add up.
- Reference data maintained independently. Product codes, cost centers, and classification hierarchies frequently exist in parallel, each team convinced theirs is the authoritative version.
- Volume that outpaces manual reconciliation. A handful of mismatched records can be fixed by hand. Hundreds of incoming files a month from dozens of departments cannot.
- No single owner for the target structure. Harmonization stalls when no one is responsible for defining what the unified format should actually look like, leaving every team to guess.
Not Sure Whether Your Sources Use the Same Formats, Definitions, and References?
A Flash Audit can identify the gaps before they show up in your reporting.
Where Data Harmonization Matters Most
A handful of recurring scenarios account for most harmonization work in practice:
- Multi-entity and multi-country consolidation — when a group operates across subsidiaries, business units, or countries, each one tends to develop its own conventions for the same underlying data long before anyone tries to combine them.
- Mergers and acquisitions — two organizations rarely use the same product codes, customer identifiers, or cost center structures. Combining their systems without reconciling these first produces duplicate or conflicting records by default.
- Multi-source reporting and BI — a dashboard pulling from several systems is only as reliable as the consistency of the data feeding it. Mismatched categories or units produce numbers that look precise but are not comparable.
- Product and reference data across formats — when different teams or departments publish data sheets, catalogs, or specifications in their own format, searching or comparing across them requires a shared structure first.
- Legacy and modern systems coexisting — older systems often carry their own historical conventions that were never reconciled with newer platforms layered on top.
These scenarios all point to the same issue: the more sources an organization combines, the more important it becomes to align meaning, format, and reference values before the data is used.
What a Complete Harmonization Approach Looks Like
A harmonization approach that holds combines four capabilities, applied as a standing process rather than a one-time cleanup.
Format Suggestion from a Target Structure
Once a target format is defined, the necessary transformations from each source format can be suggested automatically, rather than mapped by hand for every new data feed.
Reusable Transformation Rules per Source
Each incoming format gets its own defined set of transformations to reach the target structure.
Those rules are built once, then applied consistently every time new data arrives from that source.
Automated, Recurring Processing
New records get harmonized as they arrive, on a defined schedule, rather than requiring a person to manually reconcile each new batch.
Geospatial and Reference Consistency Where Relevant
Location data, classification codes, and other reference fields are unified the same way as any other field, so cross-source searches and comparisons actually work.
In Practice: Unifying Product Data Sheets Across Dozens of Formats
A major transportation and logistics organization needed to unify data sheets published by dozens of internal departments, each using its own format, to power a searchable internal portal.
What previously took weeks to months of manual compilation for each new project was industrialized into a repeatable, automated workflow.
A target format was established. Transformations from each incoming format were defined once. New data sheets — including location data for worksites, warehouses, and depots — were automatically processed as they were deposited daily by different teams.
Project risk dropped significantly because teams could start with the right input data already unified, instead of spending weeks assembling it first.
This is what data harmonization changes in practice: it turns scattered, department-specific files into a reusable structure that teams can actually search, compare, and trust.
Not Sure How Unified Your Data Actually Is Across Systems?
Request a free Flash Audit to see where formats, definitions, and references diverge across your data sources.
If you want to test harmonization rules directly, start a free trial on your own data.
Where Tale of Data Fits
Tale of Data treats harmonization and integration as one connected process, not two separate tools bolted together. The platform connects to the sources that matter — ERPs, databases, files, legacy systems — and lets teams define a target structure once, then automatically suggests the transformations needed to bring each source format into alignment with it.
Unlike integration platforms built primarily to move data between systems, Tale of Data was designed around making the result trustworthy, not just connected: semantic consistency, format standardization, and reference alignment are part of the same no-code workflow as the data movement itself, with every transformation visible, reusable, and traceable rather than buried in a script only one person understands.
This is also where the platform differs from legacy data integration vendors that treat data quality as an add-on to ETL. Harmonization isn't a separate module here — it's the layer that makes integration actually deliver something usable.

Clinical Trial Data Quality Management: Challenges and Solutions

Clinical Data Integration: Trusted Pipelines for Life Sciences
