Pharmaceutical Data Integrity: Why Validated Systems Alone Are Not Enough for AI-Ready Data
Most pharmaceutical organizations already take data integrity seriously.
Their core systems are validated. Their SOPs are documented. Their quality processes are in place. Their teams understand that critical data must be accurate, complete, traceable and available when it is needed.
Inside each system, this control is often strong.
But pharmaceutical data no longer stays inside one system.
It moves between EDC platforms, LIMS, ERP, QMS, CTMS, regulatory tools, data warehouses, spreadsheets, scripts and analytical environments. Product data moves from regulatory dossiers to manufacturing systems. Supplier records move between procurement, quality and ERP environments. Clinical data moves from EDC exports to analysis-ready datasets. Lab files are reconciled with patient identifiers, visit windows and protocol requirements.
That is where many data quality and traceability issues appear: not necessarily inside validated systems, but in the preparation layer between them.
Data is exported, mapped, transformed, merged, filtered, corrected, deduplicated or reconciled. These steps are often handled through Excel files, scripts, staging tables, vendor files or manual review workflows.
This article is not a regulatory interpretation of GxP or ALCOA+. It uses pharmaceutical data integrity as a practical lens to identify a common operational gap: the data preparation layer between systems is often less visible, less documented and harder to control than the systems themselves.
For life sciences organizations investing in AI, analytics, migrations or faster reporting, this gap matters. AI-ready pharma data requires more than validated source systems. It requires trusted, quality-controlled and explainable data flows between those systems.
Pharmaceutical Data Integrity HubUse this article as the central entry point for our content on data integrity, traceability and AI-ready pharma data. Start with the practical guide Explore related topics Assess your own data |
What pharmaceutical data integrity means in practice
Pharmaceutical data integrity means that critical data remains trustworthy throughout its lifecycle.
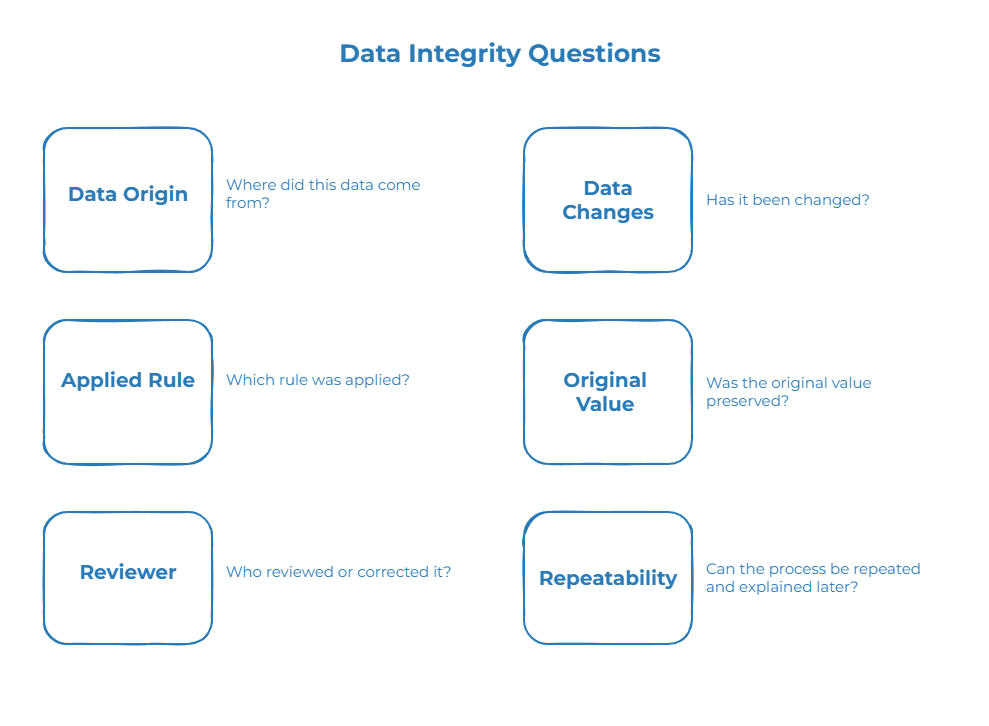
In practice, teams should be able to answer simple but important questions:
- Where did this data come from?
- Has it been changed?
- Which rule was applied?
- Was the original value preserved?
- Who reviewed or corrected it?
- Can the process be repeated and explained later?
These questions are not only relevant inside validated systems. They also apply to the files, scripts, staging tables, mappings and reconciliation processes that shape data before downstream use.
A dataset can come from a validated system and still become difficult to trust if it is transformed several times without clear documentation. A supplier record can be correct in one system and duplicated in another. A clinical export can be technically complete but still contain identifier mismatches or undocumented transformations.
That is why data integrity in the pharmaceutical industry should not be treated only as a system validation topic. It is also a data quality, data integration and traceability topic.
Why validated systems alone are not enough
Validated systems are essential.
They help control user actions, preserve audit trails, enforce workflows and document changes inside regulated environments. An EDC platform can track changes made to a clinical record. A LIMS can document actions performed on laboratory data. A QMS can preserve evidence around quality events. An ERP can manage master data under defined governance rules.
But validated systems mainly govern what happens inside their own application.
They do not automatically control every export, mapping, reconciliation, manual correction or transformation that happens after the data leaves the system.
Consider a clinical dataset moving from an EDC environment to an analysis workflow. The EDC system may be validated. The statistical environment may also be controlled. But between them, a data manager may export the dataset, merge it with LIMS results, resolve subject identifier discrepancies, apply unit conversions, flag outliers, reconcile visit windows and prepare an analysis-ready file.
Each step affects the data.
If these operations are handled in scripts, spreadsheets or staging tables without enough documentation, the organization may have strong system validation but weak cross-system traceability.
The same pattern appears in master data and operations. Product references may be corrected before ERP migration. Supplier records may be deduplicated before entering a procurement system. Manufacturing or quality data may be transformed before reporting. Clinical and lab data may be reconciled before review.
The issue is not that these steps are wrong. They are often necessary.
The issue is whether they are visible, controlled and explainable.
Where data integrity becomes fragile between systems
Many data integrity issues come from practical workarounds created for speed.
A team uses Excel because it needs to correct records quickly. A script is written because two systems do not connect easily. A staging table is created for a migration. A mapping file is shared between teams to reconcile codes. A vendor sends recurring files in a format that changes over time.
These solutions may work operationally, but they can become fragile if they are not documented and monitored.
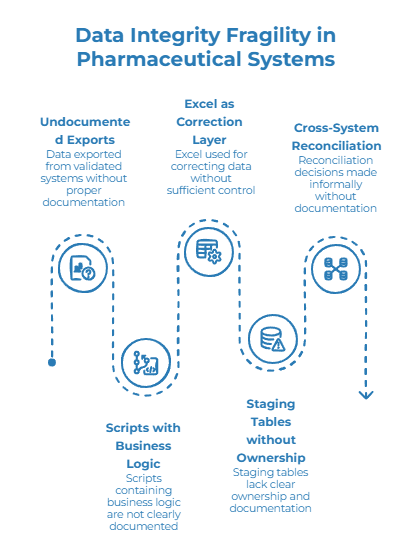
1. Undocumented exports
The moment data is exported from a validated system, part of its governance context can become harder to preserve.
An EDC export, LIMS file or ERP extract may be accurate at the time of extraction. But if the file is then filtered, merged, corrected or transformed, teams need to know what happened after the export.
Without that visibility, traceability often stops at the system boundary.
2. Scripts that contain business logic
Scripts are common in pharma data environments because they are flexible and efficient.
But scripts often contain important business logic: mapping rules, unit conversions, exclusions, deduplication choices, reconciliation rules or derived variables.
If the logic is not documented clearly, teams become dependent on the person who wrote the script. Months later, when a format changes or a reviewer asks why a value appears in the final dataset, the answer may require reverse-engineering the code.
3. Excel as a correction layer
Excel remains widely used because it is accessible and fast.
The problem is not Excel itself. The problem is when Excel becomes the main layer for correcting, reconciling or enriching critical data without enough control.
A supplier mapping file, a clinical reconciliation spreadsheet or a product reference table can all become important data preparation assets. If the original value is overwritten, the correction is not attributed, or the file version is unclear, the final dataset becomes harder to explain.
4. Staging tables without clear ownership
Staging tables are useful between source systems and downstream systems.
But they can also become hidden transformation layers.
A staging environment may contain temporary mappings, corrections or rules introduced for a specific project and reused for months. Ownership becomes unclear. Documentation becomes incomplete. Business teams may not know which rules were applied, while technical teams may not know whether the rules are still valid.
5. Cross-system reconciliation without documentation
Reconciliation is not just a technical matching exercise. It is a data decision.
When two systems disagree, someone must decide which value is trusted, which identifier becomes the reference, which source takes priority and which records need review.
If these decisions happen informally in a meeting, inside a script or through manual spreadsheet edits, the final data may be usable, but the decision path may be difficult to explain later.
ALCOA+ data integrity in the preparation layer
ALCOA+ is widely used by pharmaceutical quality teams as a framework for thinking about data integrity: Attributable, Legible, Contemporaneous, Original and Accurate, plus Complete, Consistent, Enduring and Available.
This article does not interpret regulatory obligations. But ALCOA+ data integrity can be used as a practical checklist for the data preparation layer.
For cross-system data preparation, the key questions are simple:
- Can transformations and corrections be attributed to a user, rule or documented process?
- Can data flows and mappings be understood by more than one person?
- Are changes documented when they happen, not reconstructed later?
- Is the original data preserved or traceable?
- Are quality checks applied before downstream use?
- Can the process be reviewed, repeated and explained over time?
If the answer is “no” or “partially” to several of these questions, the organization may not have a system problem. It may have a preparation-layer problem.
That is exactly where data quality, integration and lineage become important.
How to improve pharmaceutical data integrity between systems
Improving pharmaceutical data integrity does not always require replacing existing systems.
In many cases, the first step is to build a more governed data preparation layer around existing systems and before downstream use.
1. Profile critical datasets before fixing them
Many teams start by trying to correct data immediately.
A safer first step is to understand the current state: completeness, duplicates, invalid formats, inconsistent identifiers, unexpected values and missing references.
Automated profiling helps teams see where the biggest issues are before launching remediation.
For pharmaceutical teams, this can apply to product master data, supplier referentials, clinical exports, lab files, staging tables or any structured dataset used in critical processes.
2. Map data flows between systems
Teams need to understand where data comes from, where it goes and what happens in transit.
This mapping should include official integrations, but also exports, scripts, spreadsheets, staging tables, vendor transfers and manual review steps.
The goal is to make the invisible preparation layer visible.
3. Embed quality controls into the pipeline
Quality checks should not happen only at the end of the process.
Completeness checks, format validation, range controls, reconciliation rules, deduplication logic and business rules can run as data moves.
When a record fails a critical control, it should be flagged early enough for review before it reaches downstream systems, reports or analysis workflows.
4. Document transformations and reconciliation logic
Every important transformation should be easier to review and explain.
If a unit is converted, the rule should be documented. If two identifiers are reconciled, the logic should be clear. If a record is excluded, the reason should be available. If a mapping table is used, teams should know which version was applied.
Good data preparation should not require a separate reconstruction effort months later.
5. Monitor quality over time
Data quality is not stable by default.
Vendor formats change. New sources are added. Business rules evolve. Protocol amendments affect datasets. Scripts are updated. Teams reorganize.
A dataset that looks reliable today can degrade later.
Monitoring data quality over time helps teams detect completeness drops, duplicate increases, format inconsistencies or recurring anomalies before they affect reporting, audits, submissions, migrations or AI initiatives.
How Tale of Data supports pharmaceutical data integrity
Tale of Data is a no-code Data Integration platform with data quality built into every pipeline.
For life sciences teams, this means creating a governed preparation layer around existing systems, where data can be profiled, transformed, validated, deduplicated, reconciled, documented and monitored before downstream use.
Tale of Data does not replace validated clinical, quality, ERP, regulatory or analytical systems. It operates around existing systems and before downstream use, on structured exports, files, databases, staging environments, cloud sources or accessible data environments.
With Tale of Data, teams can:
- run a Flash Audit to identify completeness gaps, duplicate risks, invalid formats, inconsistent values, rule violations and potential traceability issues;
- build visual no-code data preparation flows without relying on undocumented scripts for every change;
- apply completeness checks, format validation, business rules, reconciliation controls, deduplication logic and consistency checks directly inside the flow;
- identify candidate duplicates through fuzzy matching, especially when records are similar but not identical;
- document transformations, mappings, corrections and reconciliation logic through lineage;
- monitor data quality indicators over time before they affect reports, audits, submissions, migrations or AI initiatives.
For pharma and life sciences teams, this helps qualify the data that reaches downstream systems, reports, analytics and AI initiatives.
The goal is simple: make the preparation layer more visible, controlled and explainable.
Download the Pharma Data Quality Guide
The Pharma Data Quality Guide is a practical self-assessment guide for life sciences teams working on data quality, traceability and AI-ready data foundations.

Inside the guide, you will find:
- a 20-question self-assessment to evaluate your data quality maturity;
- a 5-step framework to strengthen audit-readiness and AI-ready data flows;
- practical examples across product, supplier and clinical data;
- a glossary of essential data quality and data integrity terms.
Download the Pharma Data Quality Guide
Conclusion: Closing the data integrity gap between systems
Validated systems are essential, but they are not the full answer to pharmaceutical data integrity.
They help control what happens inside applications. The remaining risk often appears between applications: in exports, scripts, spreadsheets, staging tables, mappings, reconciliations and undocumented transformations.
For pharmaceutical organizations investing in AI, analytics, migrations or more reliable reporting, this gap is becoming increasingly important. Data must not only be available. It must be reliable, traceable, quality-controlled and explainable from source to downstream use.
The organizations that close this gap do not necessarily replace their existing systems. They build a governed data preparation layer around them — one that profiles data, embeds quality controls, documents transformations, supports reconciliation and monitors quality over time.
The first step is visibility.
Start with a Flash Audit on your highest-risk data domain and identify where your pharmaceutical data integrity gaps are today, or download the Pharma Data Quality Guide to structure your broader data quality assessment.

Clinical Data Integration: Trusted Pipelines for Life Sciences

Clinical Trial Data Quality Management: Challenges and Solutions
