Pharmaceutical Data Management: A Complete Guide for Life Sciences Teams
Pharmaceutical data management is no longer just about storing, moving or centralizing data.
It has become a foundation for audit-readiness, clinical reliability, regulatory efficiency, operational performance and AI-ready data across life sciences.
Pharmaceutical companies already rely on specialized systems: EDC, LIMS, QMS, ERP, CTMS, regulatory platforms, data warehouses and analytics tools. The problem is not a lack of systems. The problem is that critical data often loses quality, context and traceability when it moves between them.
Data is exported, transformed, reconciled, corrected, merged, deduplicated and prepared through scripts, spreadsheets, staging tables, vendor files and manual processes. That is often where data quality breaks.
For life sciences teams, poor pharmaceutical data management can delay migrations, complicate quality investigations, weaken audit preparation, create reconciliation gaps in clinical trials, increase supplier risk and reduce confidence in AI initiatives.
This article explains what pharmaceutical data management means, why it matters, where the main risks appear, and how life sciences teams can build more trusted data pipelines.
Pharma Data Quality HubUse this article as the central entry point for our Pharma Data Quality content series. Start with the practical guide Go deeper on specific topics Assess your own data |
What is pharmaceutical data management?
Pharmaceutical data management refers to the processes, standards and tools used to keep critical life sciences data accurate, complete, consistent, traceable and usable throughout its lifecycle.
It covers data used across clinical development, manufacturing, quality, procurement, supply chain, regulatory affairs, analytics and AI initiatives.
In practice, pharmaceutical data management includes product and material master data, supplier data, clinical trial data, laboratory data, quality data, regulatory data and datasets prepared for reporting, migration or AI use cases.
What makes data management in the pharmaceutical industry different is the consequence of failure.
In many industries, poor data quality creates inefficiency. In pharma, it can also create inspection risk, delayed submissions, supply chain disruption, unreliable analysis or weaker confidence in critical decisions.
A product attribute inconsistent between regulatory and manufacturing systems can slow operational decisions. A supplier record missing qualification status can create audit issues. A clinical dataset with undocumented transformations can weaken confidence before analysis.
Pharmaceutical data management is therefore not only about centralizing information. It is about making sure data can be trusted, explained and reused across critical processes.
Why pharmaceutical data management has become strategic
Life sciences organizations are under pressure to use data faster, across more systems, with stronger governance and better traceability.
Clinical development is becoming more data-rich. Modern trials may combine EDC records, laboratory data, ePRO responses, imaging measurements, wearable data, CRO files and analytical datasets. The more sources involved, the harder it becomes to maintain consistent identifiers, formats, definitions and lineage.
Master data complexity is also increasing. Products, materials, suppliers, sites and organizations are often managed across different functions and systems. ERP migrations, acquisitions and global template deployments make this fragmentation more visible.
AI adds another layer.
Life sciences teams want to use AI for trial optimization, quality monitoring, medical review, supply chain forecasting, classification, documentation and operational decision-making. But AI does not fix weak data foundations. It depends on them.
If source data is duplicated, incomplete, inconsistent or poorly documented, AI outputs become harder to trust and harder to explain.
That is why pharmaceutical data management solutions are increasingly evaluated not only on their ability to integrate data, but also on their ability to preserve quality, context and traceability as data moves between systems.
Where pharmaceutical data management breaks most often
Most pharmaceutical data issues do not appear because one system is completely broken. They appear because data moves across too many systems, teams and formats without enough control.
1. Master data is fragmented across systems
Product, material, supplier, site and organization data are often managed differently across ERP, QMS, LIMS, procurement, manufacturing and regulatory environments.
The same material may have one code in an ERP, another label in a quality system and another naming convention in a regulatory dossier. Supplier records may be duplicated across sites, regions or legacy systems. Product attributes may be correct in one platform and outdated in another.
This creates practical problems: unreliable reporting, duplicate records, unclear ownership, migration delays and poor foundations for AI.
Strong pharmaceutical data management helps teams standardize, deduplicate, reconcile and monitor these references across systems.
2. Data is integrated without being trusted
Many pipelines are built to move data, not to validate it.
They extract records, transform formats and load outputs into another system. Technically, the transfer works. Operationally, the data may still contain duplicates, missing values, inconsistent identifiers or invalid formats.
In pharma, moving poor-quality data faster only spreads the risk faster.
A trusted approach to pharmaceutical data management combines integration, validation, remediation, lineage and monitoring in the same data flow.
3. Manual reconciliation remains too present
Excel, scripts and manual reconciliation still appear in many critical pharmaceutical data flows.
They are often used because teams need speed, flexibility or a workaround when existing systems cannot handle a specific case. These approaches can solve local issues, but they are difficult to scale and hard to document.
The risk is not only operational inefficiency. It is the ability to explain and reproduce what was done when data is used for reporting, migration, quality review, clinical analysis or audit preparation.
4. Traceability is strong inside systems but weak between systems
Validated systems are essential. But they mainly control what happens inside their own applications.
The gap often appears around those systems: exports, scripts, spreadsheets, staging tables, mappings, transformations and corrections.
A dataset may come from a controlled system, but if it was transformed several times through poorly documented processes before downstream use, the final output becomes harder to explain.
This is one of the most important realities of pharmaceutical data management: the system may be controlled, but the preparation process around it may not be transparent enough.
For a deeper view of this issue, see our article on pharmaceutical data integrity.
5. Clinical data becomes difficult to reconcile
Clinical trial data comes from many sources: EDC, LIMS, ePRO, eCOA, imaging, wearables, CRO files, EHR extracts and analytical environments.
Each source may have its own identifiers, formats, units, visit windows or completeness rules.
The EDC export may be correct. The lab result may be correct. The ePRO record may be correct. But when datasets are combined, they may no longer align.
This creates reconciliation gaps before monitoring, review, analysis, database lock or submission preparation.
For more detail, read our articles on clinical data integration and clinical trial data quality management.
How to build stronger pharmaceutical data management
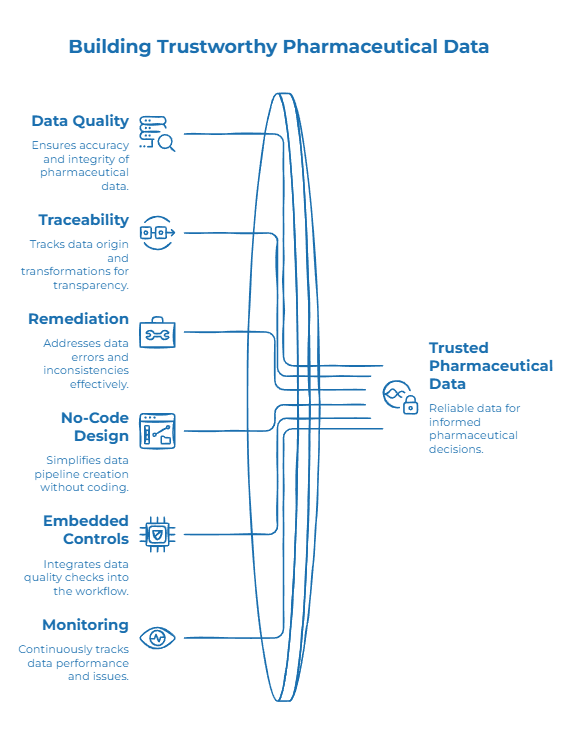
A stronger pharmaceutical data management framework starts with visibility.
Teams need to know where critical data lives, how it moves, which systems consume it and where quality issues appear. Without this map, remediation remains reactive.
The next step is profiling. Before fixing data, organizations need to understand the current state of their datasets: completeness, duplicates, invalid formats, inconsistent values, missing references and unexpected patterns.
Then comes standardization and deduplication. Product, supplier, material, site or clinical records need consistent rules for matching and consolidation. In pharma, exact matching is often not enough because names, codes, spellings, legal forms and formats vary across systems and countries.
Quality controls should then be embedded into the data flow. Completeness checks, business rules, format validation, reconciliation controls and anomaly detection should run as data moves, not only after it reaches the next system.
Lineage makes the framework easier to defend. Teams should be able to explain where a data point came from, how it was transformed, which rule was applied and which decision shaped the final output.
Finally, monitoring keeps the framework alive. Data quality degrades over time as systems change, vendors send new formats, teams update rules and new use cases appear.
To evaluate your current maturity across these dimensions, download the Pharma Data Quality Guide. It includes a practical self-assessment framework for life sciences teams working on trusted data foundations.
What to look for in pharmaceutical data management solutions
The best pharmaceutical data management solutions should not only move data from one system to another. They should help teams build trusted data flows where quality, traceability and remediation are built into the process.
For many life sciences teams, the strongest approach is a governed data integration layer with data quality built into the pipeline.
Instead of treating integration, cleansing, deduplication, remediation and monitoring as separate projects, the same workflow can connect, check, transform, document and monitor data as it moves.
Key capabilities to look for include:
- no-code or low-code pipeline design;
- embedded data quality controls;
- fuzzy matching and deduplication;
- business-friendly remediation workflows;
- lineage and processing documentation;
- monitoring over time;
- ability to operate around existing systems without replacing them.
This approach is especially useful for teams that need faster results than a multi-year transformation programme, while still improving control over critical pharmaceutical data.
How Tale of Data supports pharmaceutical data management
Tale of Data is a no-code Data Integration platform with data quality built into every pipeline.
It helps life sciences teams connect, profile, transform, deduplicate, validate, remediate and monitor data across enterprise systems and accessible data environments.
Tale of Data does not replace EDC, LIMS, CTMS, QMS, ERP or specialized business applications. It operates around existing systems and before downstream use, where data can be prepared and qualified before it reaches analytical, operational or regulated environments.
With Tale of Data, teams can:
- run a Flash Audit to identify duplicates, completeness gaps, invalid formats and rule violations in a structured dataset;
- build visual no-code data pipelines without relying on fragile scripts for every transformation;
- detect duplicates using fuzzy matching, even when records are not exactly identical;
- allow business users and data stewards to remediate data through governed workflows;
- document transformations, corrections and rules through lineage;
- monitor data quality over time before issues affect reporting, migration, audits, dashboards or AI initiatives.
For pharmaceutical teams, this can apply to product master data, supplier data, clinical datasets, staging tables, exports, partner files or other structured data domains.
The goal is simple: understand what is broken, fix what matters, and keep critical data trusted over time.
Download the Pharma Data Quality Guide
The Pharma Data Quality Guide is a practical self-assessment guide for Data Managers, MDM Leads, QA Directors and life sciences teams working on trusted data foundations.
Inside the guide, you will find:
- a 20-question self-assessment to evaluate your data quality maturity;
- a framework for building stronger audit-readiness and AI-ready data flows;
- practical examples across product, supplier and clinical data;
- a glossary of essential data quality and data integrity terms.
Download the Pharma Data Quality Guide
Conclusion: From data movement to trusted pharmaceutical data pipelines
Pharmaceutical data management is no longer only about storing, moving or centralizing data.
It is about making sure critical data remains trusted, traceable and usable across life sciences processes.
The challenge is not that organizations lack systems. They usually have many. The challenge is making sure data keeps its meaning and quality as it moves between them.
For large pharmaceutical groups, this means better control across complex global ecosystems. For mid-sized pharma, biotech and medtech organizations, it means a faster route to stronger audit-readiness and AI-ready data foundations without replacing existing systems.
The next step is simple: start by understanding the current state of your data.
Download the Pharma Data Quality Guide to structure your assessment, or run a Flash Audit to see where the first issues are hiding.

Financial Data Quality Management: Framework, Risks and Best Practices

Pharmaceutical Data Integrity for AI-Ready Data
